
Allocation Logic: Practical Operating Guide for Meshline Teams
Use Allocation Logic: Practical Operating Guide for Meshline Teams to show operators what breaks when work moves through tools without a clear owner, who should own recovery,.
Allocation Logic: Practical Operating Guide for Meshline Teams
Allocation Logic: Practical Operating Guide for Meshline Teams breaks when work moves through tools without a clear owner. For operators, the painful part is the manual recovery that follows: teams lose time recovering context that should have stayed visible, ownership is unclear, and the team has to rebuild context while the customer, lead, campaign, or report is already waiting.
This guide translates allocation logic from abstract policy into concrete implementation: where allocation decisions fail, how to design a Trigger → Owner → Exception. → Outcome operating model, exact examples and use cases, a Meshline implementation checklist, and the metrics and QA controls you need to run an. effective review queue.
Table of contents
- What allocation logic means in practical operations
- Where the workflow breaks: common failure modes
- Trigger → Owner → Exception → Outcome operating model
- Examples and use cases (exact, practical illustrations)
- Meshline implementation checklist (step-by-step)
- Metrics and QA controls for allocation logic
- How allocation logic becomes a searchable, reviewable operating layer
- Integration patterns and authority references
- Appendix: sample ownership rules and templates
What allocation logic means in practical operations
In practice, allocation logic is:
- A deterministic rule set that maps an event or record to an owner (team, queue, person) or to a credit outcome (revenue, attribution, SLA).
- An operating layer that sits between source systems and downstream actions. This operating layer enforces workflow controls and ownership rules so that decisions are predictable and auditable.
- A source of truth for exception routing and measurable outcome assignment, so every routed item has context, origin, and a timestamped decision path.
Why this matters: without clear allocation logic, organizations suffer lost leads, misattributed conversions, duplicated work, and audit gaps. With a robust allocation layer (implemented as part of MeshLine's Autonomous Operations Infrastructure), you get predictable SLAs and the ability to analyze and improve routing decisions.
Key terms you should internalize
- workflow control layer: the system that evaluates allocation rules and records the decision path.
- Workflow controls: programmatic gates and validations applied during routing.
- Ownership rules: criteria that define which owner receives a record.
- Exception routing: pathways for items that fail validation or cannot be assigned normally.
- Measurable outcome: the business-level result (owner assigned, conversion credited, ticket created).
- Review queue: a searchable list of exceptions or low-confidence assignments that humans inspect.
Where the workflow breaks: common failure modes

Allocation logic can break in predictable ways. Recognizing these failure modes lets you build targeted workflow controls.
- Data quality failure — missing or malformed keys
- Symptom: routing rules don't match because identifiers (email, customer_id) are absent or invalid.
- Control: schema validation and data quality exceptions before allocation. See ISO data quality guidance for baseline expectations: https://www.iso.org/standard/35736.html
- Conflicting ownership rules
- Symptom: two rules match the same record with different owners (e.g., region vs. product priority).
- Control: deterministic priority ordering and tie-break rules embedded in the workflow control layer.
- Latency and race conditions
- Symptom: multiple events for the same entity create inconsistent assignments.
- Control: idempotent allocation operations, versioning, and event ordering guarantees (Kafka streams or transactional writes). Kafka Streams docs: https://kafka.apache.org/documentation/streams/
- Hidden side effects and manual overrides
- Symptom: manual change bypasses rules and isn't reflected back into the system, causing audit drift.
- Control: every manual override must write an audit record back to the workflow control layer and be review-queued.
- Unclear escalation/exception paths
- Symptom: exceptions get lost in email, spreadsheets, or ad-hoc Slack channels.
- Control: structured exception routing and a review queue with SLA ownership.
- Poor observability of the decision path
- Symptom: stakeholders cannot trace why an allocation happened.
- Control: lineage and decision logs using OpenLineage and DataHub for context: https://openlineage.io/docs/spec/ and https://datahubproject.io/docs/lineage/
- Authorization and access drift
- Symptom: owners get assigned but lack permission to act (data or CRM access).
- Control: integrate allocation decisions with access control (for data stores, see Snowflake ACLs: https://docs.snowflake.com/en/user-guide/security-access-control-overview) and with identity checks (NIST access control guidance: https://csrc.nist.gov/projects/access-control-policy-tool). Also follow OWASP authorization guidance for UI/API enforcement: https://cheatsheetseries.owasp.org/cheatsheets/Authorization_Cheat_Sheet.html
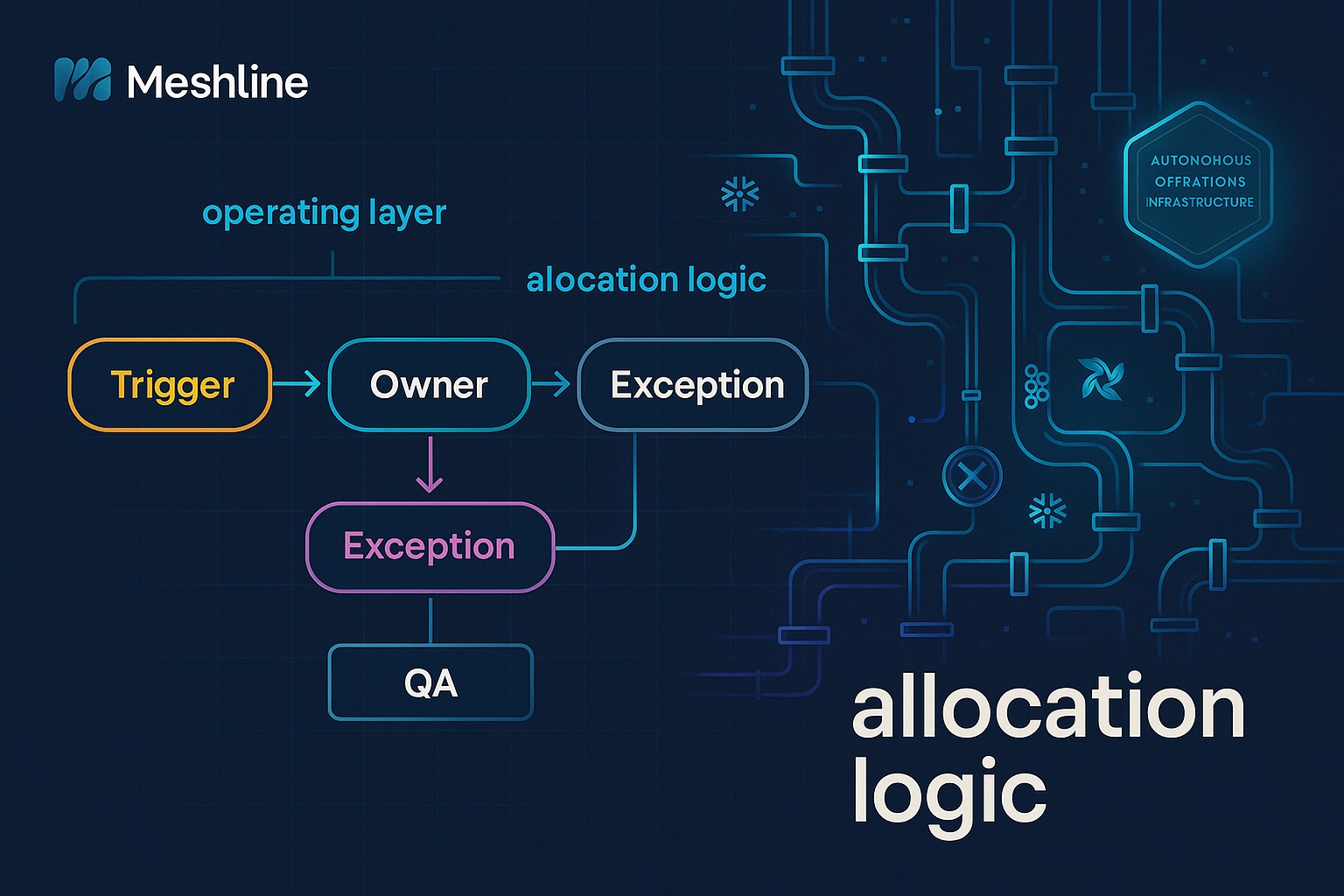
Trigger → Owner → Exception → Outcome: an operating model
A simple, repeatable model helps teams convert chaotic routing into operational predictability.
- Trigger
- Definition: the event or record that initiates allocation (lead created in CRM, conversion pixel, batch reconciliation job). Triggers must carry context: timestamps, source system id, source event id, and schema version.
- Implementation considerations: use event streaming (Kafka), scheduled batch triggers (Airflow), or a hybrid. See Apache Airflow concepts: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/index.html and Kafka Streams: https://kafka.apache.org/documentation/streams/
- Owner
- Definition: the team, user, or system responsible for the next action (sales rep, data owner, fulfillment queue).
- Ownership rules: codify assignments into a semantic layer (dbt semantic layer: https://docs.getdbt.com/docs/use-dbt-semantic-layer/dbt-sl) so decision logic is tested, reviewed, and versioned.
- Operational rule types: geography-based, product-based, round-robin, weighted allocation, SLA-based, and recently active ownership.
- Exception
- Definition: when the allocation cannot be confidently resolved or violates workflow controls (data quality, authorization, rule conflicts).
- Exception routing: send to a review queue with exact reason codes, suggested remediation, and a graded confidence score. Use standardized exception codes and route to a team or a human depending on severity.
- Outcome
- Definition: the measurable outcome resulting from allocation (owner assigned, credit given, ticket created, or escalation to legal/compliance).
- Measurable outcome: every outcome must be recorded as a transaction in the workflow control layer with: trigger id, decision path, timestamp, owner id. rule version, and evidence links (logs or query snapshots).
This model applies to lead routing, attribution, SLA assignment, and many data ownership decisions.
Examples and use cases (exact, practical illustrations)
Below are concrete examples your team can copy, adapt, and test. Each includes: trigger shape, allocation rule, exception behavior, and measurable outcome.
Example 1 — B2B lead assignment (Salesforce)
- Trigger: new lead created in marketing form with fields: email, country, product_interest, lead_score. (Inbound webhook from web form.)
- Allocation logic: if lead_score >= 80 and country == 'US' then assign to Enterprise SDR queue; else if country in ['US', 'CA'] and. product_interest == 'ProductA' then assign to Regional SDR based on zip_code mapping; else route to Inside Sales.
- Workflow controls: verify email format, check for duplicate by email or company domain, check Salesforce assignment rules snapshot: https://help.salesforce.com/s/articleView?id=sf.customize_leadrules.htm&type=5
- Exception routing: duplicates route to review queue with suggested merge action; missing email routes to a username-verification queue.
- Outcome: create Salesforce lead, write allocation decision to Meshline workflow control layer with rule_version and generate audit link.
Example 2 — Marketing attribution and crediting (Google Analytics / Google Ads / Meta)
- Trigger: conversion event from website or ad click.
- Allocation logic: apply priority attribution model for paid channels; if conversion has ad_click_id from Google Ads, apply last_ad_click credit; if multiple ad clicks, fall back to weighted time-decay model. Reference: Google Analytics attribution: https://support.google.com/analytics/answer/10596866 and Google Ads attribution models: https://support.google.com/google-ads/answer/6259715 and Meta attribution settings: https://www.facebook.com/business/help/460276478298895
- Workflow controls: verify pixel integrity, check for bot signals, ensure campaign_id maps to known campaign taxonomy.
- Exception routing: missing campaign metadata → route to marketing ops review queue with raw event payload attached.
- Outcome: record attribution decision into the data warehouse with lineage back to event stream and attribution rule version.
Example 3 — Data product ownership and SLAs (Snowflake + dbt)
- Trigger: data table freshness check fails (late ingestion).
- Allocation logic: if table_owner_team is set in dataset metadata, assign alert to owner; if owner undefined and dataset tag includes 'critical', route to. data platform on-call; else route to data steward pool.
- Workflow controls: enforce access control checks (Snowflake): https://docs.snowflake.com/en/user-guide/security-access-control-overview and validate schema against dbt models.
- Exception routing: unable to determine owner → create ticket and put record in the review queue for data steward assignment.
- Outcome: SLA ticket created; allocation recorded with rule_version and remediation steps.
Example 4 — Revenue crediting for multi-touch funnels (Marketo + CRM)
- Trigger: opportunity closed-won with linked Marketo touchpoints.
- Allocation logic: apply a Revenue Cycle Model weighting (Marketo revenue cycle model: https://experienceleague.adobe.com/docs/marketo/using/product-docs/reporting/revenue-cycle-analytics/revenue-cycle-model.html) to allocate revenue credit across touches. If touchpoints are missing channel metadata, apply default split to last non-direct touch.
- Workflow controls: verify that all touchpoints are deduplicated and anchored to canonical contact id; enforce idempotent updates to avoid double crediting.
- Exception routing: unmatched touchpoints route to marketing ops' review queue.
- Outcome: create allocation record in revenue system, with links to Marketo and CRM records.
Example 5 — Stream processing routing (Kafka + Airflow)
- Trigger: materialized event arriving on processing topic.
- Allocation logic: route event to service A if payload.type == 'transaction' and event.amount > 1000; else route to service B. Include backpressure control to avoid overloading owners.
- Workflow controls: validate schema, apply access policy, checkpoint offsets to ensure idempotence. See Kafka Streams and Airflow concepts: https://kafka.apache.org/documentation/streams/ and https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/index.html
- Exception routing: malformed event → route to dead-letter topic and push a ticket to the review queue.
- Outcome: event processed and allocation recorded in Meshline workflow control layer with offsets and lineage info.
These examples cover sales routing, attribution, data product ownership, revenue crediting, and streaming decisions. Use them as templates for your own rule sets.
Meshline implementation checklist
The checklist below is a practical rollout plan for embedding allocation logic into MeshLine's Autonomous Operations Infrastructure. Follow these steps in order and use the acceptance criteria for toggling to prod.
- Inventory triggers and owners
- Action: catalog every trigger source, owner identity format (user id, team id), and downstream measurable outcome.
- Acceptance: each trigger has a documented schema and owner mapping table.
- Define ownership rules and priorities
- Action: write machine-readable ownership rules (YAML/JSON) with priority ordering and tie-breakers.
- Acceptance: rules are stored in version control and have a review sign-off.
- Add workflow controls
- Action: define validation rules (schema, auth, de-duplication) that must pass before assignment.
- Acceptance: failed validations consistently generate exception records.
- Implement decision logging and lineage
- Action: every allocation must write a single transaction record containing trigger_id, rule_version, inputs, decision_path, owner_id, and outcome.
- Acceptance: logs are queryable and linked to data lineage tools (OpenLineage, DataHub).
- Build exception routing and review queue
- Action: create categorized exception codes, create review queue UI/API, define SLAs per category.
- Acceptance: exceptions are searchable and slotted to owners or steward pools.
- Integrate with downstream systems
- Action: implement connectors (CRM, ad platforms, data warehouse) with idempotency and back-pressure handling.
- Acceptance: connector retries and dead-letter handling configured.
- Add metrics, QA, and automated tests
- Action: implement unit tests for rules, end-to-end tests for allocation outcomes, and continuous QA monitors.
- Acceptance: test coverage thresholds met; monitors alert on drift.
- Roll out in stages
- Action: start in canary mode for 5–10% of traffic, validate results, and increase roll-out.
- Acceptance: stable metrics and no regressions in review queue volumes beyond expected.
- Governance and change control
- Action: require rule changes to go through a change review process with rollback plan and auditing.
- Acceptance: every change is versioned and has a documented business justification.
Metrics and QA controls for allocation logic
Your workflow control layer must expose KPIs and have automated QA to prevent regression.
Essential metrics
- Assignment accuracy rate: percent of assignments validated by owner or sampled audit.
- Exception rate by category: data_quality, rule_conflict, auth_failure, unknown_owner.
- Mean time to resolution (MTTR) for review queue items.
- Duplicate assignment rate: percent of records assigned more than once.
- Idempotency failure count: operations that caused non-idempotent state changes.
- SLA compliance: percent of assignments completed within target window.
- Drift detection: change in assignment distribution after rule updates.
Recommended QA controls
- Unit test ownership rules using representative record fixtures.
- Synthetic triggers: periodic synthetic events to validate routing paths and downstream integrations.
- Shadow mode comparison: run new rules in parallel (no-op mode) to compare outcomes before switching.
- Sampling audits: human review of random samples with a checklist and automated annotation back into the system.
Example QA workflow
- Daily synthetic test runs produce a parity report showing differences between active rules and candidate rule set.
- If parity difference > threshold, route to rule authors and hold outbound changes.
- Weekly audit: sample 0.1% of allocated items and validate owner acceptance; record assignment_accuracy_rate.
How allocation logic becomes a searchable, reviewable workflow control layer
The power of allocation logic comes when every decision is stored as a first-class, queryable record. This turns ephemeral routing into a searchable, reviewable workflow control layer.
Minimum schema for allocation records
- allocation_id (UUID)
- trigger_id and trigger_source
- timestamp
- rule_version
- inputs (serialized snapshot)
- decision_path (ordered list of evaluated rules and outcomes)
- owner_type and owner_id
- exception_code (nullable)
- outcome_type and outcome_metadata
- evidence_links (logs, lineage pointers)
Storing and surfacing decisions
- Store allocation records in your data warehouse (Snowflake) for analytics and in a fast lookup store (Redis/Elasticsearch) for operational UIs.
- Connect allocation records to lineage metadata via OpenLineage and DataHub so analysts can trace a measurable outcome back to the data source and the rule that executed. See OpenLineage: https://openlineage.io/docs/spec/ and DataHub lineage docs: https://datahubproject.io/docs/lineage/
- Expose a review queue UI/API that supports searches, filters by exception_code, and bulk actions (reassign, accept, escalate).
Searchable review queue features
- Full-text search over trigger payload and owner notes.
- Filters: rule_version, exception_code, time window, owner, SLA state.
- Bulk operations: reassign, apply rule patch, attach audit note.
- Audit trail: every action in the review queue writes back to the allocation record and to an immutable audit log.
Operational playbooks
- Low-severity exceptions: auto-assign to steward pool with 48-hour SLA.
- Medium-severity: notify owner and create task with 24-hour SLA.
- High-severity (compliance, legal): immediate escalation to compliance on-call and create a do-not-process flag for related triggers.
Integration patterns and authority references
Allocation logic touches many systems. Use well-documented integration patterns and lean on vendor best practices.
- CRM routing: model Salesforce assignment rules and mirror rule snapshots back into the workflow control layer for audit: https://help.salesforce.com/s/articleView?id=sf.customize_leadrules.htm&type=5
- Marketing attribution: integrate event-level and campaign metadata from Google Analytics and Google Ads and mirror attribution models as versioned functions: https://support.google.com/analytics/answer/10596866 and https://support.google.com/google-ads/answer/6259715. For Meta, verify attribution windows and settings: https://www.facebook.com/business/help/460276478298895
- Lead rotation and workflows: align with HubSpot workflows for round-robin or rotate-record patterns: https://knowledge.hubspot.com/workflows/rotate-records-with-workflows
- Revenue allocation: follow Marketo revenue cycle model thinking for multi-touch assignments: https://experienceleague.adobe.com/docs/marketo/using/product-docs/reporting/revenue-cycle-analytics/revenue-cycle-model.html
- Data access and ownership: enforce Snowflake access control patterns and link owner assignment to permission checks: https://docs.snowflake.com/en/user-guide/security-access-control-overview
- Semantic layer for rules: store canonical business entities and mapping in dbt semantic layer for testable rules: https://docs.getdbt.com/docs/use-dbt-semantic-layer/dbt-sl
- Lineage and observability: annotate allocation events with OpenLineage metadata and register decisions in DataHub lineage to support audits and root cause: https://openlineage.io/docs/spec/ and https://datahubproject.io/docs/lineage/
- Orchestration and streaming: use Airflow to schedule batch assignment validations and Kafka for high-throughput triggers: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/index.html and https://kafka.apache.org/documentation/streams/
- Security guidance: use NIST access control models and OWASP authorization best practices to ensure owners can act on assignments: https://csrc.nist.gov/projects/access-control-policy-tool and https://cheatsheetseries.owasp.org/cheatsheets/Authorization_Cheat_Sheet.html
Appendix: sample ownership rules and templates
Below are actionable rule templates you can copy into your rule engine. Use YAML or JSON and version them in your policy repo.
Sample rule: geographic + score priority (YAML)
- id: lead_assignment_v1
priority: 100
conditions:
- field: lead_score
op: >=
value: 80
- field: country
op: in
value: ['US']
action:
owner_type: queue
owner_id: enterprise_sdr_queue
- id: product_geo_assignment_v1
priority: 80
conditions:
- field: product_interest
op: equals
value: 'ProductA'
- field: country
op: in
value: ['US','CA']
action:
owner_type: team_region
owner_lookup: zip_to_region_map
Exception code taxonomy (recommended)
- EX-DQ-01: missing_required_field
- EX-DQ-02: malformed_identifier
- EX-RULE-01: rule_conflict
- EX-AUTH-01: owner_lacks_access
- EX-UNKNOWN-01: owner_not_found
Review queue SLA matrix (example)
- P0 (compliance/legal): 1 hour
- P1 (high business impact): 24 hours
- P2 (operational): 48 hours
- P3 (info/minor): 7 days
Governance checklist for rule changes
- Who requested the change and why (business justification).
- Change owner and rollback plan.
- Pre-release shadow run results and parity report.
- Stakeholder sign-off (Ops, Legal, Security, Product).
- Post-release monitoring plan.
Closing: Making allocation logic operational in Meshline
Allocation logic is not a single script or dashboard — it's an workflow control layer: a disciplined combination of workflow controls, ownership rules, exception. routing, and measurable outcomes that integrates into your Autonomous Operations Infrastructure.
Meshline teams that codify allocation logic into a versioned, testable, and reviewed workflow control layer reduce waste, increase predictability, and gain audit-quality lineage for every decision. Implement the Trigger → Owner → Exception → Outcome model, run the QA playbooks, and build a searchable review queue so exceptions become teachable moments rather than black holes.
If you follow this guide, you will have a clear path from ambiguous events to auditable measurable outcomes — with predictable SLAs and a scalable workflow control layer for future automation.
Further reading and authority documents referenced throughout:
- Google Analytics attribution: https://support.google.com/analytics/answer/10596866
- Google Ads attribution models: https://support.google.com/google-ads/answer/6259715
- Meta attribution settings: https://www.facebook.com/business/help/460276478298895
- Salesforce assignment rules: https://help.salesforce.com/s/articleView?id=sf.customize_leadrules.htm&type=5
- HubSpot lead routing: https://knowledge.hubspot.com/workflows/rotate-records-with-workflows
- Marketo revenue cycle model: https://experienceleague.adobe.com/docs/marketo/using/product-docs/reporting/revenue-cycle-analytics/revenue-cycle-model.html
- Snowflake access control: https://docs.snowflake.com/en/user-guide/security-access-control-overview
- dbt semantic layer: https://docs.getdbt.com/docs/use-dbt-semantic-layer/dbt-sl
- OpenLineage specification: https://openlineage.io/docs/spec/
- DataHub lineage: https://datahubproject.io/docs/lineage/
- Apache Airflow concepts: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/index.html
- Kafka stream processing: https://kafka.apache.org/documentation/streams/
- NIST access control: https://csrc.nist.gov/projects/access-control-policy-tool
- OWASP authorization guidance: https://cheatsheetseries.owasp.org/cheatsheets/Authorization_Cheat_Sheet.html
- ISO data quality standard: https://www.iso.org/standard/35736.html
Authority References for Operators
Practical Examples
For example, a data infrastructure, routing, attribution, and operations teams team can use Meshline to capture the signal, assign an owner, route exceptions, and. record the outcome before the next customer or revenue handoff breaks. The same workflow can be reused as a checklist, alerting rule, or review queue when volume increases.
How to use this playbook
Start with one real allocation logic a practical operating guide workflow, not a theoretical transformation program. Pick the path where work gets stuck, customers wait, or a manager has to ask, "who owns this now?" That is where the useful signal lives.
A concrete example
For Allocation Logic: Practical Operating Guide for Meshline Teams, for example, map the moment a request enters the business, the system that records it, the owner who decides the next action, and the notification that proves the work moved. If any of those four pieces are fuzzy, the workflow is still running on hope and calendar reminders. Brave, but not exactly scalable.
Common mistakes to avoid
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Do not automate a vague process. You will only make the confusion faster.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Do not let two systems disagree without a named owner for reconciliation.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Do not treat exceptions as edge cases if they happen every week. That is the process waving a tiny red flag.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Do not measure activity when the real question is whether the outcome happened.
Monday morning checklist
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Pick the workflow with the most visible handoff pain.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Write down the trigger, owner, next action, exception path, and success metric.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Find one failure mode from last week and decide how it should be routed next time.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Add one QA check that catches bad data before it becomes customer-facing work.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Review the result after seven days and tighten the rule instead of adding another meeting.
Practical operating checks
In Allocation Logic: Practical Operating Guide for Meshline Teams, use this section to turn the workflow automation idea into a visible operating decision. The goal is to make the next handoff obvious before volume increases.
Monday morning diagnostic
For Allocation Logic: Practical Operating Guide for Meshline Teams, start by checking the last five examples where the workflow stalled. Write down the trigger, the source system, the owner, the next action, and the moment the customer or lead received a response. If one of those fields is missing, the workflow is relying on memory.
First workflow to tighten
For Allocation Logic: Practical Operating Guide for Meshline Teams, step 1 is to choose one handoff and make it measurable. For example, define what should happen when a qualified lead arrives, when a content brief is approved, when a CRM record changes, or when a reconciliation exception appears. The smaller the first rule, the easier it is to prove.
Checklist before you scale
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Confirm the page or workflow has one owner.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Confirm the source system and destination system agree on the key fields.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Add one quality check that catches bad data before it reaches a reader, lead, or customer.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Add one relevant Meshline resource link that helps the reader take the next step.
- For Allocation Logic: Practical Operating Guide for Meshline Teams, Review the result after seven days and improve the rule before adding more volume.
Related Meshline resources
Use Allocation Logic: Practical Operating Guide for Meshline Teams with Organic Marketing Engine, Revenue Intel Module, Meshline glossary, and Book a Meshline demo when you want the workflow to connect back to pipeline instead of stopping at planning.