
Trigger-to-Outcome Orchestration for Agency Delivery
Fix shipment tracking when customers ask for updates before the team can explain the delay: give agency operators a clearer owner path, earlier exception checks, and a way to.
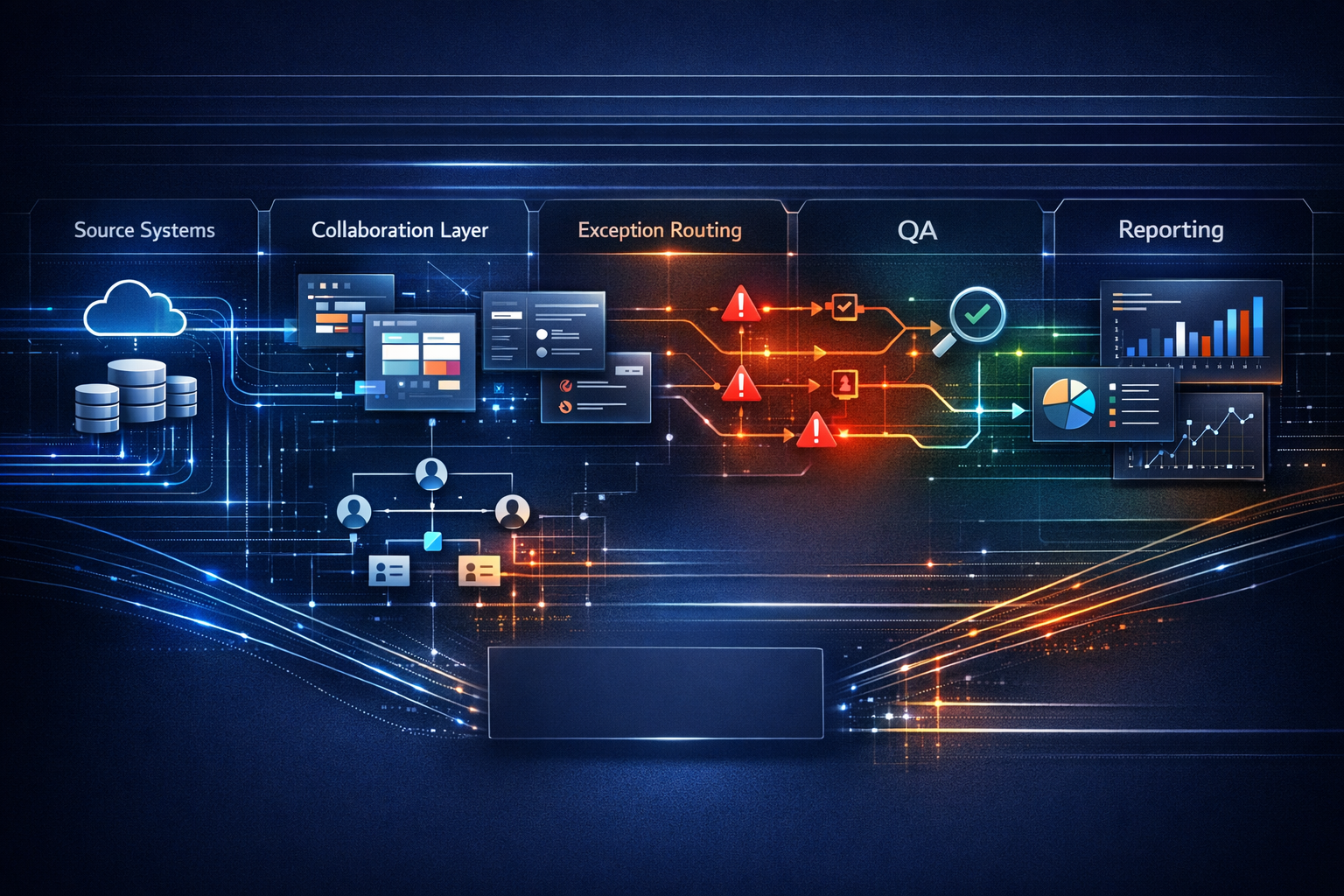
Trigger-to-Outcome Orchestration for Agency Delivery
If trigger to outcome orchestration a better feels harder than it should, the problem is usually not effort. It is the quiet mess between tools: unclear owners, missing handoffs, stale data, and a process that only works when one heroic person babysits it. This playbook shows how to make that workflow calmer, easier to inspect, and harder to break.
What this is and why it matters
Agency delivery operations face recurring problems: inconsistent handoffs, poor operational visibility, unclear ownership, and slow exception paths.Meshline agency delivery operations trigger-to-outcome orchestration reframes these problems by treating delivery as a set of trigger-to-outcome executions backed by an Autonomous Operations Infrastructure. that becomes the agency delivery operations source of truth and system of record.
Why it matters:
- Reduces manual handoffs and workflow bottlenecks.
- Provides a single agency delivery operations operating layer for routing, visibility, and ownership.
- Enables system-led execution with human-in-the-loop controls, improving agency delivery operations performance and revenue operations outcomes.
This post teaches the model, diagnoses common failure modes, and gives a practical operating model you can implement.
Key concepts and vocabulary

- Trigger-to-outcome execution: an event (lead routed, brief approved) triggers an automated path to a measurable outcome (campaign live, invoice sent).
- Autonomous Operations Infrastructure: the operating layer that automates routing, state management, and system sync across CRMs, content systems, and tools.
- Operating layer vs execution layer: the operating layer manages rules, governance, and audit trails; the execution layer runs tasks, integrations, and worker flows.
- Ownership and control: explicit assignment of responsibility for outcomes, enforced by the system-led execution model.
- Self-operating business systems: systems that carry state, decision logic, and escalation rules so teams can focus on exceptions.
The operating framework: Meshline's trigger-to-outcome orchestration
This framework maps to an agency delivery operations operating model with four core components:
- Signals and triggers (source events)
- Orchestration and routing (workflow control layer rules)
- Execution and integration (execution layer/system-led execution)
- Outcomes, audit trail, and feedback (visibility, reporting, QA)
1. Signals and triggers: capture the right events
Treat every handoff or decision as a potential trigger: brief approval, asset ready, creative review, lead routed, QA pass/fail, or contract signed. Use the workflow control layer to normalize events so agency delivery operations automation can act consistently across content operations, customer operations, and revenue operations.
2. Orchestration and routing: rules, ownership, and exception routing
Orchestration enforces agency delivery operations governance: who owns a task, how routing happens, what QA checks apply, and where exceptions go. The workflow control layer should handle agency delivery operations routing and exception path logic so human steps are small, predictable, and auditable.
3. Execution layer: integrations, system sync, and system-led execution
The delivery path performs the work: API calls to a CMS, CRM automation, lead routing engines, or a data sync. This layer must guarantee idempotency and produce an audit-friendly agency delivery operations audit trail. When possible, prefer self-operating business systems for repeated patterns and use the workflow control layer for orchestration.
4. Outcomes, measurement, and feedback loops
Outcomes must be measurable: delivery completed, campaign live, SLA met. Use the workflow control layer to centralize agency delivery operations reporting, provide operational visibility, and feed back into workflow rules and automation governance.
How Meshline applies these components (workflow control layer detail)
Meshline positions the workflow control layer as an Autonomous Operations Infrastructure for agency delivery operations. It does not replace tools; it sits above them to provide:
- A single agency delivery operations source of truth and system of record for state and ownership.
- Routing and decision logic for agency delivery operations handoff and exception routing.
- Standardized QA checks and audit trails to reduce rework and improve compliance.
- A control plane for automation governance and system sync across CRMs and content systems.
This approach lets agency operators standardize the agency delivery operations process, embed ownership rules, and accelerate time-to-outcome without large upfront custom projects.
Examples and use cases
Below are common agency delivery operations workflows and how trigger-to-outcome orchestration improves them.
Use case: Lead routing + creative brief to execution
Problem: Leads go into a CRM but creative briefs are lost in Slack. Manual handoffs cause delays and unclear ownership.
Solution: A trigger-to-outcome flow captures the CRM event, enriches the lead, creates a brief in the delivery system, assigns ownership, and starts QA checks. Exception routing handles missing data and routes to a human for completion.
Benefits: Faster lead routing, clear ownership, fewer manual handoffs, and consistent agency delivery operations reporting.
Use case: Content operations and campaign launches
Problem: Campaign launches require approvals from multiple teams and involve manual QA checks across platforms.
Solution: Meshline’s workflow control layer defines the approval workflow, enforces quality checks automatically, triggers CMS updates via the delivery path, and records the audit trail for post-launch reporting.
Benefits: Reduced workflow bottlenecks, predictable handoffs, and measurable campaign delivery time.
Use case: Client change requests and exception paths
Problem: Client requests arrive ad hoc, bypassing the official process; changes create confusion and version drift.
Solution: The workflow control layer exposes decision agency delivery operations flows that capture change requests as triggers, run automated validation, require an explicit owner. and route exceptions to the change desk with SLA enforcement.
Benefits: Controlled exception routing, fewer reworks, and clear accountability.
Implementation steps: from map to live operations
Below is a practical playbook you can use to deploy a trigger-to-outcome operating model.
- Map value streams
- Inventory delivery processes: creative requests, campaign launches, content operations, revenue operations handoffs, CRM automation, lead routing.
- Identify triggers, decision points, and common failure modes.
- Define outcomes and SLAs
- For each flow, define expected outcome, owner, and SLA for completion.
- Choose the workflow control layer surface
- Decide the scope for Autonomous Operations Infrastructure and the system of record.
- Model orchestration rules
- Encode routing, quality checks, exception routing, and ownership rules in the workflow control layer. Include decision rules for manual handoffs.
- Build execution adapters
- Implement integrations for system sync with CRM, CMS, analytics, and other tools; ensure idempotency and observability.
- Implement QA and monitoring
- Add quality checks, audit trails, and performance dashboards; instrument with observability best practices.
- Pilot with a single flow
- Start with a high-impact workflow (e.g., lead-to-brief-to-delivery) and iterate.
- Expand and codify governance
- Harden automation governance, update the agency delivery operations checklist, and document ownership rules.
Implementation checklist (condensed)
- Map triggers and outcomes
- Define ownership and SLAs
- Create routing and exception rules
- Implement quality checks and audit trail
- Build integrations and system sync
- Pilot, measure, iterate, and scale
Ownership, QA, and governance: rules and failure modes
Clear ownership and QA reduce ambiguity. Below are recommended rules and common failure modes with mitigations.
Ownership rules
- Every outcome must have one primary owner and one backup owner recorded in the workflow control layer.
- Ownership changes must be an auditable operation (system-led work or explicit handoff recorded).
- Owners are responsible for closure or for escalating along a defined exception path.
quality checks and control points
- Define automated quality checks where possible (format validation, required assets, budget thresholds).
- Insert human QA only where judgment is required.
- Log every QA pass/fail to the audit trail and trigger remediation flows for failures.
Common agency delivery operations failure modes and mitigations
- Missing data: use required-field enforcement at the trigger and automated enrichment where possible.
- Manual handoffs that skip the workflow control layer: use system sync and notifications; audit exceptions.
- Routing loops or ownership conflicts: implement deterministic routing and tie-breaker rules.
- Integration drift and system sync failures: implement retries, backoff, and alerting with incident rules.
Exception paths
- For recoverable errors (missing assets), route to the owner with a timebox and SLA escalation.
- For systemic failures (API outage), pause non-essential flows, surface an incident to ops, and notify affected owners.
- Maintain an explicit exception routing map so operators know where to escalate each class of problem.
quality checks, audit trails, and performance monitoring
QA must be built into the orchestration, not bolted on. Key checks:
- Schema validation for inputs (required fields, types)
- Ownership verification (owner assigned and available)
- SLA timers and age-of-task metrics
- End-to-end execution logs that are searchable and immutable
Performance monitoring should track:
- Flow completion rates and mean time to outcome
- Number and type of exceptions and manual handoffs
- Agency delivery operations visibility metrics: pending tasks by owner, overdue items, and bottlenecks
Use industry practices for observability and incident management as part of the workflow control layer; for example, align to the DORA DevOps capabilities and instrument with observability patterns from Datadog’s knowledge center.
Governance: automation policies and approval gates
Automation governance should include:
- A catalog of automated flows with owners and runbooks
- Approval gates for flows that affect billing, privacy, or client SLAs
- Periodic reviews of routing logic and quality checks
- A rollback plan for any automation change
Refer to standards and frameworks for governance and risk, such as NIST's Cybersecurity Framework and ISO guidance for operational controls (ISO 62085).
Example failure mode table (short)
- Symptom: Repeated manual handoffs causing delays. Root cause: Missing orchestration rules. Fix: Model routing and ownership in workflow control layer.
- Symptom: Conflicting owners on a task. Root cause: No deterministic routing. Fix: Add tie-breaker rules and audit ownership changes.
- Symptom: Integration errors during launch. Root cause: No idempotency or retries. Fix: Harden delivery path with retries and backoff.
Practical patterns for agency operators
- Start with the smallest valuable flow: a lead-to-brief trigger-to-outcome execution.
- Codify ownership rules: one owner per outcome, with backup and SLAs.
- Automate validation and quality checks as early as possible to prevent rework.
- Use the workflow control layer to hide tool complexity and provide a single pane of agency delivery operations visibility.
Checklist: pre-deployment and live operations
- [ ] Cataloged triggers and outcomes
- [ ] Defined owners and backup owners for every outcome
- [ ] SLA and escalation rules set
- [ ] Orchestration rules encoded in workflow control layer
- [ ] Execution adapters with idempotency and retries
- [ ] quality checks automated where possible
- [ ] Audit trail and reporting dashboards in place
- [ ] Exception routing map documented
- [ ] Runbook and rollback plans for automation changes
External references and further reading
- For process design and operations principles, see Harvard Business Review on operations management: HBR: Operations Management.
- For workflow automation fundamentals, see IBM on workflow automation: IBM: Workflow Automation.
- For observability patterns relevant to monitoring delivery flows, see Datadog: Datadog Observability Knowledge Center.
- For incident and escalation practices, see PagerDuty’s incident management resources: PagerDuty Incident Management Guide.
- For CI/CD and execution best practices that apply to the delivery path, see GitHub Actions: GitHub Actions Documentation and GitLab CI: GitLab CI Documentation.
- For platform engineering and operating-layer maturity, see CNCF platform engineering maturity model: CNCF Platform Maturity Model.
- For data synchronization patterns and system-led integrations, see Airbyte: Airbyte Resources.
- For customer data and event catalog practices that inform triggers, see Segment’s academy: Segment Academy.
- For security and standards guidance, consult NIST’s Cybersecurity Framework: NIST Cybersecurity Framework and ISO operational standards: ISO 62085.
- For developer practices around infrastructure-as-code that apply to the delivery path, see Terraform docs: Terraform Documentation.
- For accessibility and content standards in content operations, see W3C WCAG: W3C WCAG Standards.
- For onboarding and human-centered operations, see Nielsen Norman Group: NNGroup Onboarding Practices.
- For measuring DevOps and delivery performance, see DORA: DORA DevOps Capabilities.
- For configuration and orchestration examples in CI/CD, see CircleCI: CircleCI Configuration Reference.
Next steps and rollout cadence
- Select a pilot flow (4–6 weeks): map triggers, owners, and outcomes.
- Build orchestration rules and one execution adapter; run a closed pilot.
- Measure mean time to outcome and exceptions; refine quality checks.
- Expand to adjacent flows and codify governance.
If you'd like help mapping a pilot and building the workflow control layer, Book a strategy call.
Closing: operating-layer behavior you can expect
When done right, a trigger-to-outcome orchestration gives agency operators consistent routing, concise ownership, automated quality checks, and clear exception paths. Meshline’s operations infrastructure idea is to provide that workflow control layer so teams can run faster, with better visibility and fewer manual handoffs.
_alt: Diagram of trigger-to-outcome orchestration showing triggers feeding an workflow control layer, delivery path integrations, and outcomes with audit trail and ownership._
How to use this playbook
Start with one real trigger to outcome orchestration a better workflow, not a theoretical transformation program. Pick the path where work gets stuck, customers wait, or a manager has to ask, "who owns this now?" That is where the useful signal lives.
A concrete example
For Trigger-to-Outcome Orchestration for Agency Delivery, for example, map the moment a request enters the business, the system that records it, the owner who decides the next action, and the notification that proves the work moved. If any of those four pieces are fuzzy, the workflow is still running on hope and calendar reminders. Brave, but not exactly scalable.
Common mistakes to avoid
- For Trigger-to-Outcome Orchestration for Agency Delivery, Do not automate a vague process. You will only make the confusion faster.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Do not let two systems disagree without a named owner for reconciliation.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Do not treat exceptions as edge cases if they happen every week. That is the process waving a tiny red flag.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Do not measure activity when the real question is whether the outcome happened.
Monday morning checklist
- For Trigger-to-Outcome Orchestration for Agency Delivery, Pick the workflow with the most visible handoff pain.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Write down the trigger, owner, next action, exception path, and success metric.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Find one failure mode from last week and decide how it should be routed next time.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Add one QA check that catches bad data before it becomes customer-facing work.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Review the result after seven days and tighten the rule instead of adding another meeting.
Practical operating checks
Use this section to turn the agency delivery idea into a visible operating decision. The goal is to make the next handoff obvious before volume increases.
Monday morning diagnostic
For Trigger-to-Outcome Orchestration for Agency Delivery, start by checking the last five examples where the workflow stalled. Write down the trigger, the source system, the owner, the next action, and the moment the customer or lead received a response. If one of those fields is missing, the workflow is relying on memory.
First workflow to tighten
For Trigger-to-Outcome Orchestration for Agency Delivery, step 1 is to choose one handoff and make it measurable. For example, define what should happen when a qualified lead arrives, when a content brief is approved, when a CRM record changes, or when a reconciliation exception appears. The smaller the first rule, the easier it is to prove.
Checklist before you scale
- For Trigger-to-Outcome Orchestration for Agency Delivery, Confirm the page or workflow has one owner.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Confirm the source system and destination system agree on the key fields.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Add one quality check that catches bad data before it reaches a reader, lead, or customer.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Add one relevant Meshline resource link that helps the reader take the next step.
- For Trigger-to-Outcome Orchestration for Agency Delivery, Review the result after seven days and improve the rule before adding more volume.
Related Meshline resources
Use this agency delivery article with Organic Marketing Engine, Revenue Intel Module, Meshline glossary, and Book a Meshline demo when you want the workflow to connect back to pipeline instead of stopping at planning.