
Prompt Approval Meaning: Practical Guide for Operators
Prompt Approval Meaning: Practical Guide for Operators helps operators spot where automated decisions move faster than review and recovery paths, then tighten ownership,.
Prompt Approval Meaning: Practical Guide for Operators
If prompt approval meaning what it means feels harder than it should, the problem is usually not effort. It is the quiet mess between tools: unclear owners, missing handoffs, stale data, and a process that only works when one heroic person babysits it. This playbook shows how to make that workflow calmer, easier to inspect, and harder to break.
What "prompt approval meaning" means in practical operations
Prompt approval meaning is not just a dictionary definition. In operations, it is an explicit, auditable policy and set of runtime controls that determine:
- Which prompts require human review before sending to or after receiving from a model.
- Who is responsible (ownership rules) for approving, rejecting, or escalating prompts.
- The decision criteria (acceptance criteria, risk thresholds, compliance checks).
- Where approvals are recorded in the operating layer so they can be searched and traced to outcomes.
This definition ties prompt-level decisions to measurable outcome expectations (for example, compliance score, conversion rate, or incident rate) and integrates those decisions with workflow controls and exception routing rules.
In Meshline’s Autonomous Operations Infrastructure, the prompt approval meaning is implemented as a formal operating layer that sits between requesters (marketing, ops, product) and the LLM model endpoints. That layer enforces policies, orchestrates review queues, captures metadata, and triggers downstream metric updates.
Authority and standards to consider when you design this layer include OpenAI safety best practices, the NIST AI Risk Management Framework, and OWASP LLM Top 10. See the resources section for links.
Why prompt approvals matter: measurable outcomes and risk trade-offs

Approvals are not a checkbox. They are the control point where operators balance speed versus risk and link prompt decisions to measurable outcomes. Examples of measurable outcomes you might connect to prompt approvals:
- Compliance score for regulated content (e.g., finance or healthcare disclosures).
- Brand safety rate: percent of outputs that pass brand-guardrails.
- Conversion lift or CTR changes from AI-generated copy.
- Average time to resolution for customer interactions when agent prompts are modified.
- Incident rate: policy violations per thousand prompts.
When you attach measurable outcome targets to approval rules, approval becomes a feedback mechanism: operators can relax or tighten workflow controls when outcomes fall outside expected ranges.
Where the workflow breaks: common failure modes
Real-world prompt approval workflows tend to fail in predictable ways. Design for and instrument against these failure modes:
- Unclear ownership rules
- Problem: Nobody is clearly responsible, so approvals stall in the review queue.
- Fix: Map prompts to owners based on taxonomy (domain, risk level, product area) and enforce time-based SLAs.
- Review queue overload
- Problem: Volume spikes cause long backlog and operators bypass approvals.
- Fix: Automate triage, batch low-risk prompts for deferred review, and add exception routing for urgent needs.
- Non-actionable decision criteria
- Problem: Reviewers lack specific acceptance criteria and return inconsistent judgments.
- Fix: Use templates and checklists with objective checks (e.g., contains prohibited term list, legal clause present).
- Poor traceability
- Problem: Decisions aren't searchable or linked to outcomes, so no learning loop.
- Fix: Store prompt, version, approval decision, reviewer rationale, and outcome metrics in the operating layer.
- Escalation friction
- Problem: Exceptions require domain experts, but the path to escalate is manual and slow.
- Fix: Build automated exception routing and SLA-driven escalation based on risk tier.
- Drift between approval intent and deployment
- Problem: An approved prompt is modified in code or reused in a different context without reapproval.
- Fix: Enforce binding references (IDs) and require reapproval if prompt text or metadata changes.
Addressing these failure modes minimizes manual rework, reduces policy drift, and preserves the integrity of approvals in the long run.
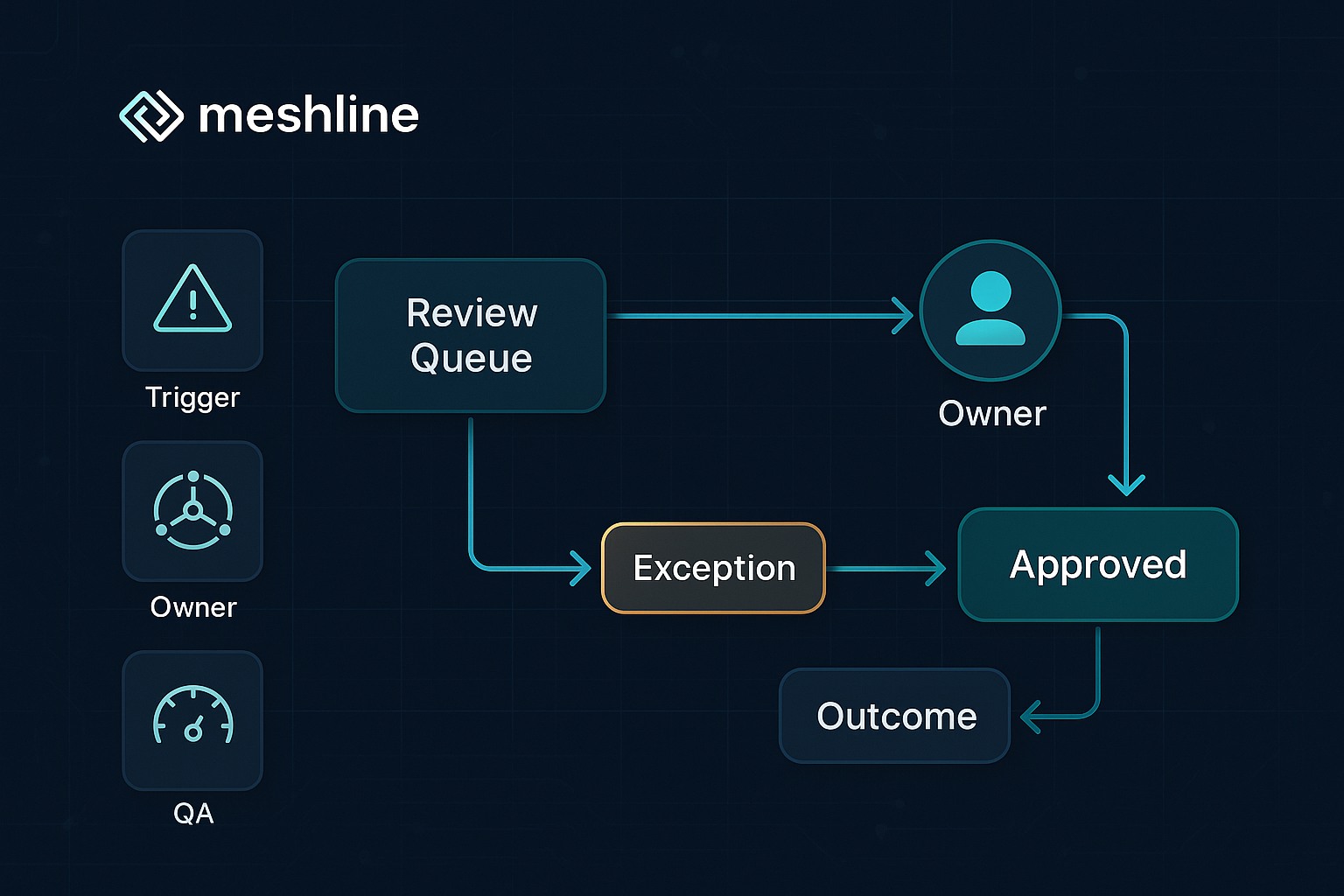
Trigger -> Owner -> Exception -> Outcome: the operational model
A simple, reproducible model for prompt approvals is the Trigger -> Owner -> Exception -> Outcome flow. Each execution path should be defined in the operating layer and enforced by workflow controls.
- Trigger: An event that enters a prompt into the approval pipeline. Examples: new creative prompt submission, model-generated content flagged by automated filters, or a scheduled policy re-review.
- Owner: The individual or role assigned by ownership rules to make the decision. Owners can be per-domain SMEs, legal reviewers, or delegated reviewers. Ownership rules are typically deterministic (based on taxonomy, risk tier, or product area).
- Exception: If the owner rejects the prompt or identifies a policy breach, exception routing moves the item to a different flow — legal review, content rewrite, or urgent block. Exception routing must be explicit and auditable.
- Outcome: The final status and associated measurable outcome. Outcomes include Approved, Approved with Edits, Rejected, Escalated, or Auto-Approved (with risk tiering). Each outcome should update linked metrics in the workflow control layer.
Example flow (concrete):
- Trigger: Marketing submits a new customer acquisition prompt labeled "Paid Social: Landing A/B" (risk tier: low).
- The workflow control layer auto-triages by keyword and risk tier and routes it to the marketing owner (ownership rules: product=Paid Social -> owner=Growth Lead).
- Owner reviews using a checklist (no disallowed claims, brand tone OK). Approves with a small phrasing edit.
- Outcome set to "Approved with Edits". The workflow control layer records the final prompt ID, reviewer ID, time-to-approval, and links to the draft creative.
- Metric update: increments 'approved_prompts' metric and schedules A/B test. If outcome causes CTR changes outside expected band, system opens a review loop.
Exact examples and use cases
Below are detailed, actionable use cases that show how prompt approval meaning is applied in practice.
Use case 1: Marketing copy for regulated industry (finance)
- Trigger: Marketer submits a loan-product prompt that includes interest rates.
- Ownership rules: Risk tier = high -> owner = Compliance SME.
- Workflow controls: Prompt blocked from production until compliance approves.
- Exception routing: If compliance is unavailable within SLA (8 hours), route to backup legal reviewer; if still unavailable (24 hours), generate time-bound temporary hold and notify leadership.
- Measurable outcome: Compliance pass rate and time-to-publish. Compliance failures must be <1% per month.
Use case 2: Sales enablement email sequences
- Trigger: Sales ops creates a personalized outreach prompt.
- Ownership rules: Risk tier = low -> owner = Sales Enablement Manager.
- Workflow controls: Auto-approve if prompt matches approved templates; otherwise route to review queue.
- Exception routing: If owner rejects, route to content writer for rewrite with inline comments.
- Measurable outcome: Response rate lift at 7 and 30 days after deployment; maintain <0.2% unsubscribe or complaint rate.
Use case 3: Customer support augmentation
- Trigger: Agent uses an assistant prompt to draft a policy-related response.
- Ownership rules: Real-time review queue with peer-review fallback for high-risk cases.
- Workflow controls: For high-risk intents (legal, safety), require pre-send approval. For low-risk, allow post-send review with automated logging.
- Exception routing: If agent flags a potential escalation, route to Tier 2 and mark conversation for human follow-up.
- Measurable outcome: First-contact resolution and escalation rate.
Use case 4: Product UX microcopy experiments
- Trigger: Product team proposes UI microcopy change across checkout.
- Ownership rules: Owner = Content Design -> auto-approve for low-risk phrasing.
- Workflow controls: Link prompt version to feature flag. Require reapproval if text changes after feature rollout.
- Exception routing: If user testing shows increased drop-off, route to content team for revision.
- Measurable outcome: Conversion delta and churn impact.
Each use case shows how to map the abstract concept of prompt approval meaning into concrete, operational controls.
Meshline implementation checklist (practical step-by-step)
This checklist is written for teams implementing prompt approval controls in Meshline’s Autonomous Operations Infrastructure but can be adapted for other platforms.
- Define taxonomy and risk tiers
- List prompt categories (marketing copy, legal notices, system prompts, agent scripts).
- Assign risk tiers (low, medium, high) with objective criteria.
- Set ownership rules
- Map categories and risk tiers to owners (role, backup, escalation path).
- Document time-based SLAs for approvals.
- Build the workflow control layer entry point
- Capture prompt metadata (author, prompt text, risk tier, context, intended outcome).
- Generate a unique prompt ID and version.
- Implement automated triage and workflow controls
- Run static checks and policy filters (prohibited terms, PII detection).
- Auto-route to review queue, auto-approve low-risk items, or block high-risk items pending human review.
- Create reviewer templates and acceptance criteria
- Provide checklists: legal, brand, safety, factual accuracy tests.
- Include explicit instructions for edits, rejection reasons, and escalation triggers.
- Establish exception routing paths
- Define what happens on rejection: rewrite, legal escalation, or immediate block.
- Automate notifications and escalations.
- Integrate outcome tracking
- Link approvals to outcomes (publish event, A/B test, campaign ID).
- Push events to analytics and incident systems.
- Auditability and searchability
- Store prompt, decision, rationale, reviewer, and timestamps in an indexed store.
- Add tags and full-text search to support post-hoc review.
- Metrics and QA controls
- Implement dashboards and alerts for SLA breaches, approval latency, and policy violation trends.
- Continuous feedback loop
- Run weekly reviews: check outcome metrics, adjust risk tiers and acceptance criteria.
Use this checklist as a release checklist before enabling production traffic from any new approval flow in MeshLine.
Metrics and QA controls: what to measure and how to act
Design metrics that tell you whether your prompt approval layer is working and whether outcomes match expectations. Use a mix of operational, quality, and business metrics.
Operational metrics
- Approval latency: median and 95th percentile time from trigger to final decision.
- Queue depth: number of items pending per risk tier.
- SLA compliance: percent of approvals meeting SLA.
Quality metrics
- Reject rate by owner and category.
- Consistency score: agreement rate between reviewers on the same prompt sample.
- Post-deployment policy violations (per 10k prompts).
Business metrics
- Conversion or engagement lift vs. control for approved prompts.
- Incident reduction tied to prompt approval (e.g., fewer customer complaints).
Controls and QA techniques
- Reviewer calibration: periodic sessions where reviewers score the same set of prompts and reconcile differences.
- Sampling: automatically sample auto-approved low-risk prompts for post-send review to validate the triage logic.
- Canary releases: roll out new prompt templates to a small cohort before broad deployment.
- Automated monitors: use model-monitoring hooks (e.g., Vertex AI model monitoring) and telemetry (OpenTelemetry traces) to detect anomalies in model responses that might indicate prompt mismatch or drift.
Set alert thresholds so that when a metric crosses a tolerance band (for example, a sudden increase in post-deployment complaints), the system automatically opens. an investigation and may tighten approval rules by risk tier.
How this becomes a searchable, reviewable workflow control layer
An workflow control layer makes approvals discoverable and actionable. Key design elements:
- Immutable records with rich metadata
- Store prompt text, prompt ID, author, version, approvals, reviewer rationale, and linked outcomes.
- Full-text and tag search
- Index prompt text and metadata so you can search by intent, product area, or rejection reason.
- Traceability to runtime events
- Link approvals to runtime requests and model responses. Use distributed tracing and event IDs to follow a prompt from approval to production (OpenTelemetry traces are useful here).
- Queryable audit trails
- Provide APIs and UIs that let auditors and operators query by time range, owner, or outcome and export records for compliance checks.
- Review queue UI and integrations
- Provide reviewers with contextual panes: original prompt, model outputs, acceptance checklist, and business context. Integrate with Slack/email and ticketing systems for notifications.
- Searchable version history
- Every change to a prompt must create a new version; the workflow control layer should allow diffing versions and require reapproval when significant changes occur.
Example implementation detail: store the approval artifact in a single JSON document with fields for prompt_text, risk_tier, owner_id, decision, rationale, linked_event_ids, and metrics_summary. Index the document in a search engine (Elasticsearch, OpenSearch, or a managed vector DB with metadata search) so that business owners can find approvals quickly and tie them to outcomes.
Tooling and integrations
A robust implementation uses a mix of automated checks, CI-style gates, and human review tools. Consider the following integrations:
- Policy scanners and static checks: detect PII, disallowed claims, or regulated terms before reaching a reviewer.
- Model monitoring: use providers’ model monitoring capabilities (for example, Google Vertex AI model monitoring) to detect data drift or output anomalies.
- Tracing and observability: instrument requests with OpenTelemetry traces to link approval IDs to runtime calls and latency.
- Ticketing and notifications: integrate approvals and exceptions with Slack, Jira, or ServiceNow to surface urgent items.
- Audit and governance frameworks: align approval rules with frameworks like the NIST AI Risk Management Framework and ISO/IEC 42001.
Authority links and resources are embedded below for operational teams to consult as they build controls.
Governance, standards, and how to scale with policies
To operate at scale, treat prompt approvals like change control in traditional IT: codify rules, automate low-risk paths, and reserve human review for edge cases. Useful governance practices:
- Policy-as-code: codify approval policies and validate them in CI before deployment.
- Role-based access and least privilege: limit who can change ownership rules or exempt prompts from review.
- Periodic audits and calibration sessions: align reviewers on acceptance criteria and update policies when outcomes drift.
Standards and frameworks to reference while building your governance program include:
- NIST AI Risk Management Framework and generative AI profile for risk assessment and governance guidance.
- OWASP LLM Top 10 for security-oriented checks of LLM applications.
- ISO/IEC 42001 for AI management systems and organizational controls.
Embed links to these authoritative resources in your governance docs to ensure reviewers and auditors can trace the provenance of rules and controls:
- OpenAI safety best practices: https://platform.openai.com/docs/guides/safety-best-practices
- OpenAI prompt engineering: https://platform.openai.com/docs/guides/prompt-engineering
- NIST AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework
- NIST generative AI profile: https://www.nist.gov/itl/ai-risk-management-framework/generative-ai-profile
- OWASP LLM Top 10: https://owasp.org/www-project-top-10-for-large-language-model-applications/
- MITRE ATLAS: https://atlas.mitre.org/
- ISO/IEC 42001 AI management: https://www.iso.org/standard/81230.html
- Google secure AI framework: https://blog.google/technology/safety-security/introducing-googles-secure-ai-framework/
- Microsoft responsible AI: https://www.microsoft.com/ai/responsible-ai
- Anthropic responsible scaling policy: https://www.anthropic.com/responsible-scaling-policy
- IBM AI governance: https://www.ibm.com/topics/ai-governance
- Salesforce Einstein Trust Layer: https://www.salesforce.com/artificial-intelligence/trusted-ai/
- HubSpot AI content assistant: https://knowledge.hubspot.com/ai-tools/use-ai-assistants
- Google Vertex AI model monitoring: https://cloud.google.com/vertex-ai/docs/model-monitoring/overview
- OpenTelemetry traces: https://opentelemetry.io/docs/concepts/signals/traces/
Operational playbook: sample templates and checklists
Below are short, copy-pasteable templates to operationalize your prompt approvals.
Reviewer checklist (short):
- Does the prompt contain disallowed terms or PII? (Yes/No)
- Is the factual claim verifiable or flagged for verification? (Yes/No)
- Is the tone in line with brand guidelines? (Yes/No)
- Is the regulatory content present and correct? (Yes/No)
- Decision: Approve / Approve with Edits / Reject / Escalate
- Rationale (required): short explanation and any requested edits.
Exception routing matrix (example):
- Reject -> Content rewrite by author -> Re-submit (lowers risk)
- Escalate (compliance/legal) -> Compliance SME -> Decision within 8 hrs
- Safety violation -> Immediate block -> Security incident created
Prompt metadata schema (suggested fields):
- prompt_id: string
- version: integer
- author_id: string
- created_at: timestamp
- risk_tier: enum(low, medium, high)
- category: string
- owner_id: string
- decision: enum(pending, approved, approved_with_edits, rejected, escalated)
- decision_at: timestamp
- rationale: text
- linked_event_ids: array
- metrics_summary: object
These templates form the basis of your workflow control layer and make approvals reproducible and auditable.
Closing: how operators use this to run better systems
Prompt approval meaning is an operational construct: it turns a conceptual governance requirement into a repeatable, measurable, and searchable workflow control layer. Operators use it to:
- Enforce workflow controls and reduce accidental policy violations.
- Assign and automate ownership rules so approvals don’t stall in the review queue.
- Configure exception routing that prevents business blocks while protecting risk-sensitive areas.
- Tie each approval to measurable outcomes, enabling continuous improvement.
Meshline and MeshLine position this workflow control layer within a larger Autonomous Operations Infrastructure: approval artifacts are first-class events in the system, searchable, traceable. with OpenTelemetry traces, and linked to downstream metrics and monitoring. When done right, prompt approval becomes both a guardrail and a learning signal — not an impediment to speed.
For practical next steps: run the Meshline implementation checklist, instrument basic metrics (approval latency, queue depth, post-deployment policy violations), and run a two-week sampler on auto-approved prompts to validate the triage logic.
If you need concrete templates or a jump-start plan to integrate approvals into your pipelines or into MeshLine workflows, build a minimal workflow control. layer that captures prompt_id, decision, and linked_event_ids, wire it to your review queue, and iterate from there.
References and further reading
- OpenAI safety best practices: https://platform.openai.com/docs/guides/safety-best-practices
- OpenAI prompt engineering: https://platform.openai.com/docs/guides/prompt-engineering
- NIST AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework
- NIST generative AI profile: https://www.nist.gov/itl/ai-risk-management-framework/generative-ai-profile
- OWASP LLM Top 10: https://owasp.org/www-project-top-10-for-large-language-model-applications/
- MITRE ATLAS: https://atlas.mitre.org/
- ISO/IEC 42001 AI management: https://www.iso.org/standard/81230.html
- Google secure AI framework: https://blog.google/technology/safety-security/introducing-googles-secure-ai-framework/
- Microsoft responsible AI: https://www.microsoft.com/ai/responsible-ai
- Anthropic responsible scaling policy: https://www.anthropic.com/responsible-scaling-policy
- IBM AI governance: https://www.ibm.com/topics/ai-governance
- Salesforce Einstein Trust Layer: https://www.salesforce.com/artificial-intelligence/trusted-ai/
- HubSpot AI content assistant: https://knowledge.hubspot.com/ai-tools/use-ai-assistants
- Google Vertex AI model monitoring: https://cloud.google.com/vertex-ai/docs/model-monitoring/overview
- OpenTelemetry traces: https://opentelemetry.io/docs/concepts/signals/traces/
Appendix: Quick diagnostic questions for your current approval flows
- Is there a single source of truth for prompt ownership rules?
- Can you map every approval to a measurable business outcome?
- Do you have automated triage that prevents low-risk prompts from overwhelming reviewers?
- Are approval artifacts searchable and linked to runtime events?
Answering these will quickly show where your current workflow breaks and which items to prioritize when building an workflow control layer in Meshline’s Autonomous Operations Infrastructure.
Authority References for Operators
Practical Examples
For example, a AI governance, marketing operations, and workflow design teams team can use Meshline to capture the signal, assign an owner, route exceptions. and record the outcome before the next customer or revenue handoff breaks. The same workflow can be reused as a checklist, alerting rule, or review queue when volume increases.
How to use this playbook
Start with one real prompt approval meaning what it means workflow, not a theoretical transformation program. Pick the path where work gets stuck, customers wait, or a manager has to ask, "who owns this now?" That is where the useful signal lives.
A concrete example
For Prompt Approval Meaning: Practical Guide for Operators, for example, map the moment a request enters the business, the system that records it, the owner who decides the next action, and the notification that proves the work moved. If any of those four pieces are fuzzy, the workflow is still running on hope and calendar reminders. Brave, but not exactly scalable.
Common mistakes to avoid
- For Prompt Approval Meaning: Practical Guide for Operators, Do not automate a vague process. You will only make the confusion faster.
- For Prompt Approval Meaning: Practical Guide for Operators, Do not let two systems disagree without a named owner for reconciliation.
- For Prompt Approval Meaning: Practical Guide for Operators, Do not treat exceptions as edge cases if they happen every week. That is the process waving a tiny red flag.
- For Prompt Approval Meaning: Practical Guide for Operators, Do not measure activity when the real question is whether the outcome happened.
Monday morning checklist
- For Prompt Approval Meaning: Practical Guide for Operators, Pick the workflow with the most visible handoff pain.
- For Prompt Approval Meaning: Practical Guide for Operators, Write down the trigger, owner, next action, exception path, and success metric.
- For Prompt Approval Meaning: Practical Guide for Operators, Find one failure mode from last week and decide how it should be routed next time.
- For Prompt Approval Meaning: Practical Guide for Operators, Add one QA check that catches bad data before it becomes customer-facing work.
- For Prompt Approval Meaning: Practical Guide for Operators, Review the result after seven days and tighten the rule instead of adding another meeting.
Practical operating checks
In Prompt Approval Meaning: Practical Guide for Operators, use this section to turn the workflow automation idea into a visible operating decision. The goal is to make the next handoff obvious before volume increases.
Monday morning diagnostic
For Prompt Approval Meaning: Practical Guide for Operators, start by checking the last five examples where the workflow stalled. Write down the trigger, the source system, the owner, the next action, and the moment the customer or lead received a response. If one of those fields is missing, the workflow is relying on memory.
First workflow to tighten
For Prompt Approval Meaning: Practical Guide for Operators, step 1 is to choose one handoff and make it measurable. For example, define what should happen when a qualified lead arrives, when a content brief is approved, when a CRM record changes, or when a reconciliation exception appears. The smaller the first rule, the easier it is to prove.
Checklist before you scale
- For Prompt Approval Meaning: Practical Guide for Operators, Confirm the page or workflow has one owner.
- For Prompt Approval Meaning: Practical Guide for Operators, Confirm the source system and destination system agree on the key fields.
- For Prompt Approval Meaning: Practical Guide for Operators, Add one quality check that catches bad data before it reaches a reader, lead, or customer.
- For Prompt Approval Meaning: Practical Guide for Operators, Add one relevant Meshline resource link that helps the reader take the next step.
- For Prompt Approval Meaning: Practical Guide for Operators, Review the result after seven days and improve the rule before adding more volume.
Related Meshline resources
Use Prompt Approval Meaning: Practical Guide for Operators with Organic Marketing Engine, Revenue Intel Module, Meshline glossary, and Book a Meshline demo when you want the workflow to connect back to pipeline instead of stopping at planning.