
Automatizar la provisión de infraestructura sin perder el control operativo
Guía práctica para crear automatizaciones de infraestructura que sean rápidas y auditables: qué debe registrar un disparador, quién es responsable, cómo manejar excepciones y qué controles introducir.
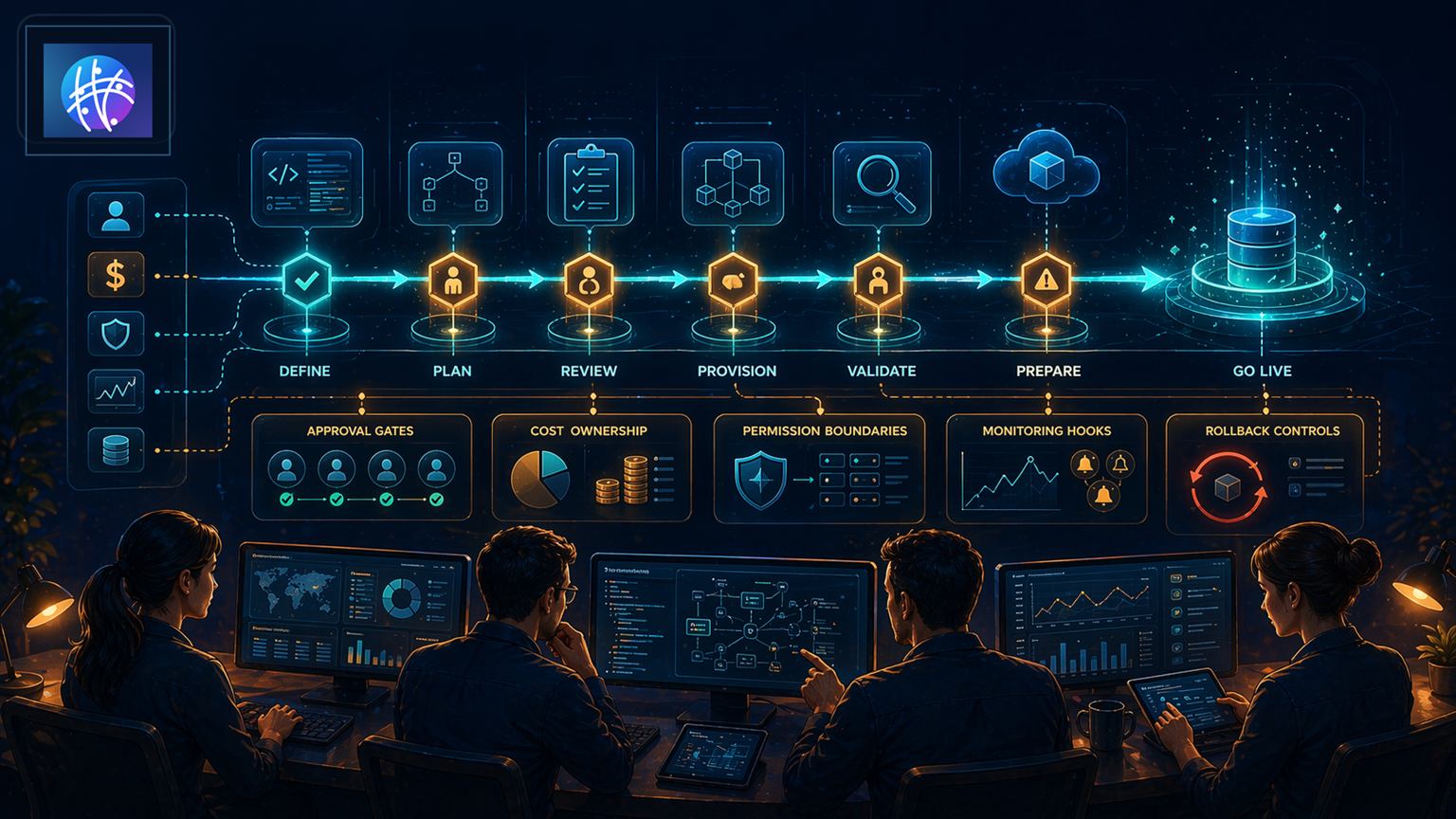
Automatizar la provisión de infraestructura sin perder el control operativo
La provisión automatizada puede acelerar despliegues y entornos, pero también genera problemas si se pierde la trazabilidad, la propiedad o la observabilidad. Esta guía explica cómo diseñar automatizaciones que no solo crean recursos, sino que dejan evidencia, asignan responsables, aplican controles y ofrecen rutas de excepción y recuperación.
Por qué importa una provisión automatizada con control
Automatizar no es solo ahorrar tiempo. Es transformar la creación de recursos en un proceso repetible y auditado. Si una máquina crea una base de datos, una cola o permisos, el equipo debe poder responder a preguntas básicas:
- Quién solicitó ese recurso y con qué propósito
- Qué sistema o costo carga con ese recurso
- Qué permisos y alcance tiene
- Cómo se monitoriza y quién reacciona ante alertas
- Cómo se revierte o limpia cuando ya no hace falta
Si la automatización no responde a estas preguntas, terminarás con instalaciones sin dueño, permisos permanentes por error y facturas inesperadas.
Modelo operativo: disparador, responsable, excepción y resultado
Un flujo confiable debe documentar cuatro elementos clave en cada provisión:
- Disparador: el punto de entrada que recoge la solicitud y su contexto. Puede ser un formulario, un issue en un repo, un mensaje en Slack o un catálogo de servicios. El disparador debe adjuntar metadatos y no perderlos durante el flujo.
- Responsable: quien aprobó y quien mantiene. Conviene diferenciar solicitante, propietario funcional y propietario técnico. Registrar ambos evita ambigüedades sobre quién recibe alertas y quién aprueba el borrado.
- Ruta de excepción: condiciones que detienen la automatización y la elevan a revisión humana. Ejemplos: falta de tags, coste estimado por encima de umbral, permisos elevados o ausencia de plan de recuperación.
- Resultado: criterios verificables que confirman que el recurso está listo para usarse. No basta con "creado". Debe incluir etiquetas, monitorización activa, propietario asignado y notas de recuperación.
Ejemplos prácticos
Ejemplo 1 — Entorno de staging para un cliente
- Disparador: plantilla en el catálogo con datos del cliente
- Validaciones automáticas: naming, etiquetas de coste, alcance de red
- Acciones: crear recursos, vincular secretos, añadir reglas de despliegue y conectar alertas
- Resultado esperado: entorno marcado como listo con propietario, enlace a runbook y política de caducidad
Ejemplo 2 — Solicitud de acceso temporal
- Disparador: formulario con objetivo, duración y sistemas a acceder
- Validaciones: comprobar que el solicitante tiene aprobación funcional, coste y auditoría habilitada
- Excepción: permisos de administrador requieren revisión manual y aprobación en 24 horas
- Resultado: credenciales con expiración automática, registro de quién pidió y por qué
Ejemplo 3 — Nueva integración o cola en producción
- Disparador: issue en repo con checklist de confiabilidad
- Validaciones: latencia esperada, SLOs y owner de escalado
- Acciones: provisionar, conectar monitoreo, crear alerta en equipo responsable
- Resultado: integración visible en panel de observabilidad y con plan de rollback documentado
Decisiones operativas que realmente importan
Antes de elegir herramientas, responde estas preguntas:
- Qué puede cambiar la automatización
Detalla si la automatización puede crear recursos, modificar permisos, desplegar código o ajustar monitoreo. Cada tipo requiere niveles de autorización distintos.
- Dónde se registra el estado
Define la fuente de verdad. ¿Un sistema de control de estado como Terraform, una base de datos de activos o un ticketing central? Evita que la automatización solo confirme internamente sin exponer estado a la organización.
- Cómo se detecta drift
Establece comprobaciones periódicas que comparen estado deseado y real. El drift no es solo un error técnico: es un fallo de confianza operacional.
- Dónde entra el juicio humano
Automatiza lo repetible, reserva revisiones humanas para cambios de alto impacto: aumentos de coste, permisos amplios y recursos que afectan a producción.
Rutas de excepción y políticas de pausa
Define claramente qué condiciones deben pausar la automatización y qué datos deberán acompañar la decisión de continuar:
- Falta de tags obligatorias o propietario de coste: pausa y rechaza hasta completar metadatos
- Coste estimado por encima del umbral: pausa y requiere aprobación del responsable financiero
- Permisos privilegiados: pausa y exige revisión de seguridad
- Ausencia de plan de recuperación: pausa y pide runbook antes de provisión
Para cada excepción, registra quién fue notificado, el plazo para resolverla y el criterio para reanudar la ejecución.
Controles de calidad y auditoría
Incluye controles automáticos y revisiones periódicas:
- Tags obligatorias y validación de naming
- Enlace a owner y ticket original en metadatos
- Monitoreo y alertas conectadas antes de marcar como listo
- Pruebas de integridad post-provisión: checks de latencia, logs y permisos
- Revisión trimestral de recursos provisionados para eliminar lo no usado
Estos controles facilitan auditorías internas y ayudan a responder preguntas regulatorias o fiscales.
Qué suele fallar primero en producción
- Recursos sin dueño que siguen facturando
- Permisos temporales que nunca expiran
- Ausencia de monitoreo, que convierte un fallo en sorpresa de cliente
Detectar estos puntos comunes permite priorizar controles bajos en esfuerzo y alto en impacto.
Patrón de despliegue y rollout incremental
- Empieza con un flujo pequeño y repetible: por ejemplo, crear un entorno de staging simple
- Ejecuta contra casos reales y revisa cinco ejecuciones para validar evidencia y propiedad
- Ajusta reglas de excepción y controles después de la primera iteración
- Expandir a más tipos de provisión cuando el patrón sea fiable
Este enfoque reduce sorpresas y facilita recuperación si algo sale mal.
Recursos y enlaces internos
Si necesitas integrar la automatización con catálogos de servicios o productos internos, revisa las páginas de producto de Meshline en /products y las soluciones de marketing y revenue en /products/organic-marketing-engine y /products/revenue-intel-module. Para más lecturas y artículos relacionados visita /blog o contacta a nuestro equipo en /contact.
Siguiente paso práctico
Mapea hoy mismo un flujo repetible para una necesidad concreta: define disparador, validaciones, propietario, checks de monitorización y ruta de recuperación. Ejecuta el flujo cinco veces con casos reales y evalúa si cada provisión contiene la evidencia necesaria para que cualquier miembro nuevo del equipo entienda qué pasó y cómo actuar.
Implementar provisión automatizada con control no es eliminar humanos, es preservar juicio donde importa y automatizar lo que es repetible y verificable. Si necesitas apoyo para diseñar el primer flujo, empieza por el checklist del rollout y contacta a nuestro equipo en /contact.
Lecturas relacionadas
Para seguir el mismo tema desde otros angulos operativos: