
Gobernanza práctica del cómputo para agentes de IA y automatizaciones
Define propietarios claros, límites de gasto, prioridades y revisiones para evitar gasto invisible y degradación operativa en agentes de IA y procesos automatizados.
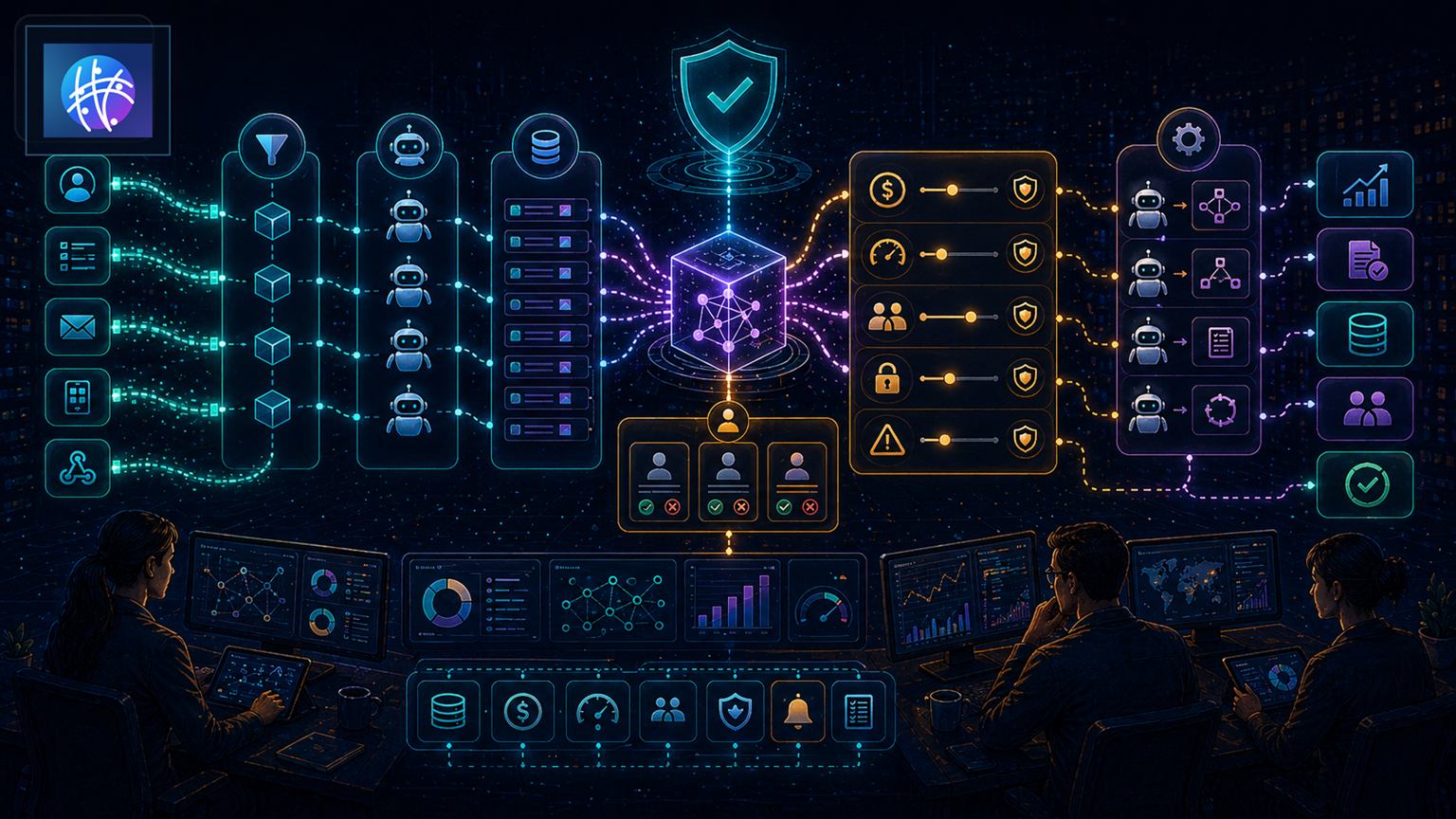
Gobernanza práctica del cómputo para agentes de IA y automatizaciones
El cómputo deja de ser un coste invisible cuando empieza a moldear la fiabilidad, la velocidad y el presupuesto del negocio. Para equipos operativos, la pregunta no es solo «¿puede ejecutarse este trabajo?», sino «¿quién lo supervisa, cuánto cuesta, qué prioridad tiene y qué ocurre cuando su uso se dispara?». Este artículo ofrece un proceso operativo claro para que agentes de IA, tareas automatizadas y pipelines no se conviertan en gasto fantasma.
Por qué hace falta gobernanza del cómputo hoy
Los agentes de IA y las automatizaciones generan consumo continuo: invocaciones a modelos, búsquedas vectoriales, llamadas a herramientas, reintentos y logs. Sin un marco de control, ese consumo crece sin dueño, produce facturas sorprendentes y compite con tareas críticas al nivel de la plataforma.
Consecuencias comunes:
- Trabajos sin propietario que siguen ejecutándose porque «alguien los necesitó una vez».
- Agentes que reintentan indefinidamente y multiplican coste por ticket.
- Jobs de baja prioridad compitiendo por recursos con workflows cliente-facing.
- Decisiones de ahorro que rompen procesos críticos porque solo se mira la factura.
Este enfoque propone controles prácticos: intake, clasificación, propietario, límites y revisión de resultado.
Camino operativo: intake, clase, propietario, límite y outcome
- Intake: registra por qué existe la carga. ¿Es una exportación para un cliente, una actualización de reporting, un agente que responde tickets o un experimento?
- Clase: etiqueta como experimental, operativa o crítica. Cada clase tiene controles distintos.
- Propietario: asigna una persona o equipo responsable de coste y resultado (producto, datos, operaciones, finanzas).
- Límite: define presupuesto, concurrencia, tasa de reintentos y caducidad automática si es experimental.
- Outcome: mide frescura, impacto de negocio y frecuencia de uso; programa revisiones periódicas.
Incluye este diagrama visual en tu documentación:

Ejemplos prácticos y decisiones operativas
Ejemplo 1 — Refresco de reporting:
- Situación: un job nocturno consume créditos de data warehouse. Antes fue crítico; ahora nadie lo abre.
- Decisión operativa: revisar dueño y dependencia downstream; si no hay consumo, degradar frecuencia a diaria y marcar revisión trimestral.
- Control: alerta por disminución de vistas del dashboard y caducidad automática si 2 ciclos pasan sin uso.
Ejemplo 2 — Agente que procesa tickets de soporte:
- Situación: el agente llama al LLM, refresca embeddings y reintenta al fallo; coste por ticket se dispara.
- Decisión operativa: fijar un tope de reintentos, limitar llamadas a modelos por minuto y medir reducción de tiempo humano por ticket.
- Ruta de excepción: si el agente falla por más de N tickets en una hora, abrir un incidente al propietario y degradar a modo de sólo logging.
Ejemplo 3 — Pipeline de datos de producción:
- Situación: pipeline crítico con alta latencia y coste en picos.
- Decisión operativa: protección de prioridad, guardrails de autoscaling y plan de rollback; aprobar cambios mayores por operaciones y producto.
- Control de calidad: pruebas de rendimiento en entorno staging y umbrales de alerta en latencia y coste.
Niveles de gobernanza: cómo aplicar controles según riesgo
No todos los trabajos necesitan el mismo proceso. Define tres niveles mínimos:
- Nivel 1 — Experimental:
- Presupuesto reducido, expiración automática, prioridades bajas.
- Owner claro y marcado como experimento.
- Nivel 2 — Operativo:
- Monitoreo de fallos, alertas de presupuesto y revisión periódica (mensual/trimestral).
- Límites de concurrencia y reintentos conservadores.
- Nivel 3 — Crítico/Producción:
- Prioridad protegida, alertas 24/7, plan de rollback, aprobación para cambios y visibilidad ejecutiva.
Decisión operativa: asigna el nivel en el intake y automatiza políticas (por ejemplo, que los jobs sin etiqueta sean degradados a experimental hasta que un owner los valide).
Rutas de excepción y comunicación humana
Las reglas automáticas son necesarias, pero las excepciones requieren juicio:
- Normal path: reglas aplican (caducidad, límites, alertas). El job sigue o caduca según la política.
- Excepción operativa: el owner puede solicitar una excepción temporal con justificación y plan de mitigación (duración limitada y condiciones de salida).
- Escalado: si el coste o la degradación exceden umbrales, se notifica a finanzas y a producto; decisiones mayores requieren aprobación de operaciones y producto.
Ejemplo de flujo de excepción:
- Owner solicita extensión de presupuesto por N días y aporta métricas de impacto.
- Operaciones valida riesgos técnicos; finanzas valida impacto presupuestario.
- Aprobación condicionada a revisiones diarias y plan de salida.
Controles de calidad y métricas a vigilar
Métricas operativas mínimas por workload:
- Coste por periodo (diario/semanal/mensual).
- Latencia media y pico.
- Volumen de invocaciones y tasa de reintentos.
- Tasa de uso del resultado (por ejemplo, vistas del reporte).
- Número de incidentes o degradaciones atribuibles.
Controles automáticos:
- No permitir workloads sin tag de propietario en producción.
- Límite de reintentos por defecto (ej. 3) y rate limits.
- Presupuesto por workspace o equipo con alertas a owner.
- Caducidad automática para experimentos sin validación.
Controles manuales:
- Revisiones trimestrales de cargas top-10 por coste.
- Auditorías post-mortem cuando un job causa interrupción.
Despliegue por fases (rollout pattern)
- Piloto con una clase de workloads (ej. reporting o agentes de soporte).
- Añadir campos obligatorios en el intake: owner, clase, presupuesto, prioridad.
- Revisar top workloads por coste, reintentos y valor de negocio.
- Automatizar alertas y caducidades; conectar rutas de excepción.
- Extender a otros dominios y documentar playbooks.
Consejo: empieza por las 5 cargas que más cuestan y las 5 que más reintentan. Su impacto y visibilidad facilitan adopción.
Recursos operativos y enlaces útiles
- Si gestionas producto y marketing, revisa cómo conectar señales con /products y /products/organic-marketing-engine.
- Para revenue y métricas de negocio, integra con /products/revenue-intel-module.
- Busca más artículos y guías en /blog.
- Si necesitas apoyo o consultoría para implantar estas políticas, escríbenos en /contact.
Siguiente paso práctico
Audita tus cinco cargas más costosas esta semana. Para cada una, responde: ¿quién es el owner?, ¿cuál es la clase?, ¿qué límite tiene?, ¿con qué frecuencia se revisa el outcome?, ¿existe una ruta de excepción? Crea etiquetas de owner y clase en tu sistema de intake, configura alarmas básicas y aplica una caducidad automática para experimentos.
La gobernanza del cómputo es una práctica operativa: comienza con reglas sencillas, automatiza lo repetitivo y guarda la revisión humana para las decisiones que realmente importan. Esto evita facturas sorpresivas y mantiene el foco en las cargas que generan valor.
Lecturas relacionadas
Para seguir el mismo tema desde otros angulos operativos: