
Plan práctico de correlación de eventos para equipos de operaciones
Guía operativa para reducir ruido de alertas y convertir señales dispersas en acciones: identidad de evento, enriquecimiento, enrutamiento de dueño, rutas de excepción y controles de calidad.
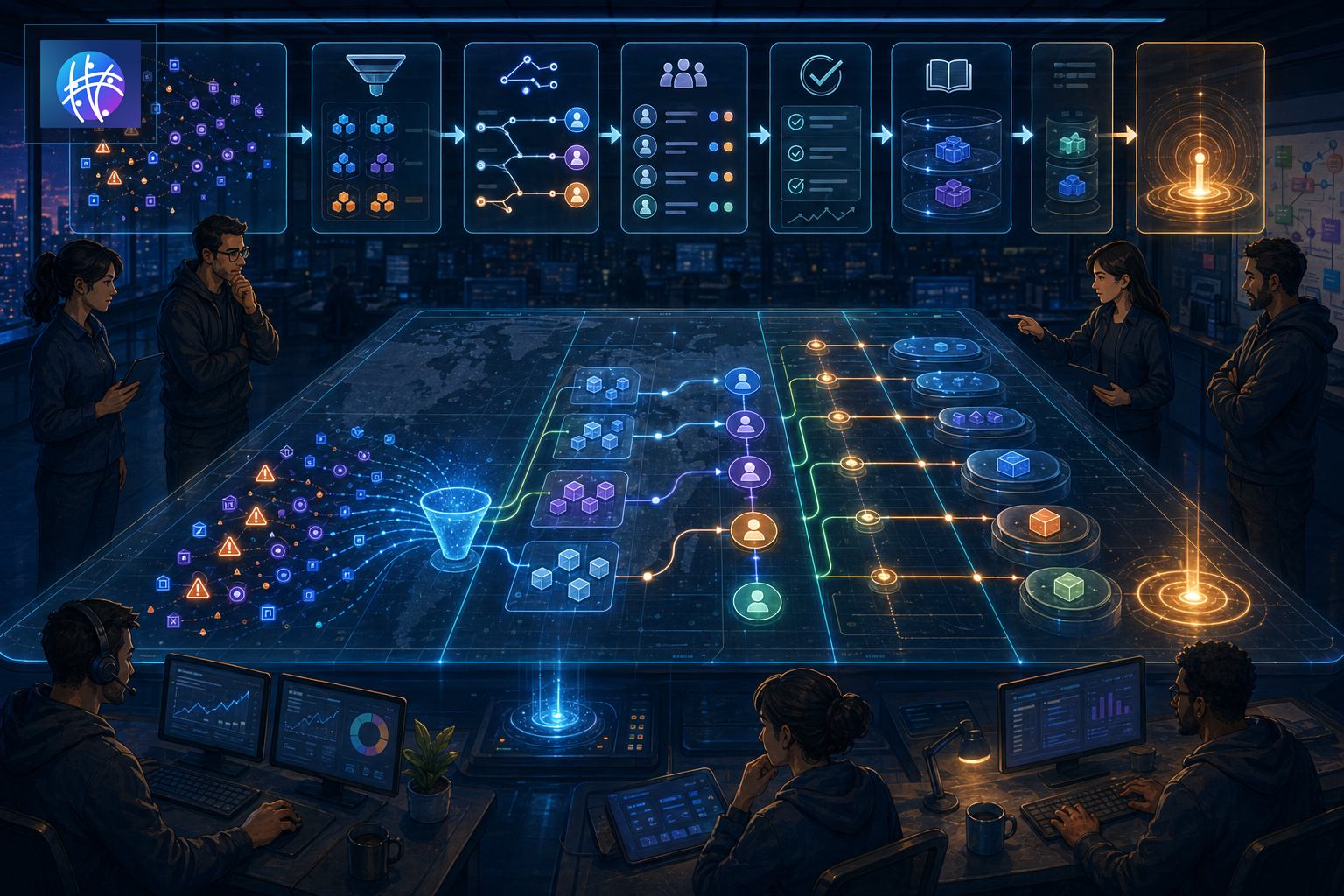
Plan de correlación de eventos para equipos de operaciones

La correlación de eventos no es solo una función de observabilidad: es la capa que convierte alertas dispersas en decisiones operativas claras. Esta guía explica cómo implantar un flujo práctico para que cada señal lleve a un dueño, una acción y aprendizaje reutilizable.
¿Por qué importa la correlación en operaciones?
Los equipos de operaciones sufren cuando las señales se fragmentan: informes contradictorios, contexto perdido y tiempo de reacción aumentado. Una correlación eficaz reduce el ruido y preserva la historia completa del incidente: qué falló, a quién afecta, por qué importa y qué se hizo.
Decisión operativa clave: prioriza correlaciones que cambien la acción (propietario, prioridad, bloqueo de workflow). Si una regla solo agrupa sin alterar el siguiente paso, es probable que sea cosmética.
Modelo práctico: señal, contexto, propietario, gravedad y resultado
- Señal: cualquier alerta o evento (error de pago, webhook fallido, cola en backlog, pico en tickets).
- Contexto: cliente, orden, integración, ventana de despliegue, versión, datos previos.
- Propietario: equipo responsable (desarrollo, revenue ops, soporte, datos, finanzas).
- Gravedad: impacto técnico vs impacto de negocio.
- Resultado: resolver, reintentar, pausar workflow, o crear tarea de prevención.
Ejemplo operativo: un error en el webhook de pagos, una notificación de soporte y un retraso en el despacho comparten el mismo ID de pedido: la correlación debe agruparlos y enrutar al equipo de pagos con contexto de cliente y órdenes afectadas.
Ruta operativa: ejemplo paso a paso
- Identidad del evento: asignar un ID de correlación (p. ej. order_id, sync_id, campaign_id).
- Recolección de evidencia: adjuntar logs, payloads, timestamps y capturas relevantes.
- Agrupación inicial: reglas determinísticas (mismo servicio, mismo ID, ventana de tiempo).
- Enriquecimiento: añadir campos de negocio (cliente, SLA, propietario anterior).
- Enrutamiento: mapear a un dueño según reglas de propiedad.
- Acción automática o humana: notificar, abrir incidente, pausar workflow o escalar.
- Cierre y aprendizaje: guardar artifact con acciones, reglas usadas y recomendaciones.
Ruta de excepción típica: si la correlación encuentra múltiples propietarios potenciales (p. ej. integraciones compartidas entre datos y backend), abrir un incidente informal con ambos equipos y marcar como "requiere propietario final". Si hay riesgo de reprocesos (pagos, estados financieros), bloquear reintentos automáticos hasta verificación humana.
Casos de uso frecuentes y decisiones operativas
- Incidentes de atención: reducir duplicados, mostrar alcance y acelerar asignación de dueño.
- Fallos en sincronizaciones de datos: conectar el fallo técnico con dashboards y reportes de negocio.
- Automatizaciones y agentes IA: distinguir retries normales de loops, separar errores de herramientas de errores de negocio.
- Agrupamiento por cliente impactado: priorizar respuestas cuando un cliente o cuenta aparece en múltiples señales.
Decisiones a definir para cada caso:
- Claves de correlación obligatorias (customer_id, workflow_id).
- Regla para supresión de duplicados (ventana temporal, misma firma de error).
- Acciones automáticas permitidas (notificación leve vs. pausa de proceso).
Diagnóstico y controles antes del enrutamiento
Antes de enviar a un dueño, el sistema debería comprobar:
- ¿Es un duplicado exacto o relacionado?
- ¿Comparte cliente, orden, integración o ventana temporal con otros eventos?
- ¿La gravedad se evalúa por fallo técnico o por impacto al cliente?
- ¿El siguiente paso es seguro para automatizar?
Controles de calidad mínimos:
- Registro del artefacto de incidente (eventos fuente, regla aplicada, enriquecimiento, dueño, acciones).
- Métricas: tiempo hasta comprensión (time-to-context), tiempo hasta dueño, tasa de misagrupación.
- Revisión semanal de correlaciones con logs y muestras aleatorias.
Reglas, IA triage y revisión humana
Reglas determinísticas son la base: mismo servicio, mismo error signature, mismo workflow_id. Son fáciles de auditar y predecibles.
La IA aporta valor para patrones ambiguos: sugerir dueño, resumir evidencia o identificar campos faltantes. Regla operativa: la IA puede proponer acciones, pero no debe ejecutar reversiones de estado crítico sin aprobación humana.
Ejemplo de uso combinado: las reglas agrupan eventos y la IA sugiere el propietario; si la confianza supera umbral y el impacto es bajo, la plataforma notifica automáticamente; si el impacto es alto, la sugerencia va a revisión humana.
Qué suele fallar en producción
1) Compresión sin contexto: menos alertas pero sin motivo, lo que dificulta priorizar.
2) Confusión de propietarios: grupos que acaban en un buzón común sin dueño claro.
3) Exceso de confianza en reglas: las reglas funcionan en escenarios normales y fallan en picos o despliegues.
4) Pérdida de aprendizaje: incidentes cerrados sin registrar ajustes en reglas o decisiones tomadas.
Mitigación práctica: mantener una lista de excepciones conocida, forzar rutas de propietario en familias críticas y registrar cambios a reglas con razones y responsable.
Patrones de despliegue y controles de calidad
1) Piloto por familia de eventos: elegir un tipo (fallos de pago, sync CRM, picos en soporte).
2) Definir claves de correlación y mapa de propietarios.
3) Implementar reglas determinísticas y métricas iniciales (TTR, TTD, tasa de falsas agrupaciones).
4) Revisión semanal con ajustes: mejorar campos de enriquecimiento, corregir propietarios y actualizar supresión.
5) Automatizar acciones seguras (notificaciones, creación de incidentes), mantener humanas las reversiónes críticas.
Controles de QA:
- Test de regresión de reglas en ventanas históricas.
- Guardar snapshot de reglas antes de cambios en producción.
- Simulacros mensuales con incidentes compuestos para validar rutas de propietario.
Ejemplos de reglas y rutas de excepción
- Regla: si evento.service == "crm-sync" y payload.workflow_id existe, agrupar por workflow_id y enrutar a equipo-datos.
- Excepción: si payload.customer_tier == "enterprise" entonces notificar también a soporte-estratégico.
- Regla IA: si tres o más firmas de error distintas aparecen pero comparten customer_id, sugerir "impacto cliente" y escalar a owner-general.
Siguiente paso práctico
1) Selecciona una familia de eventos piloto (p. ej. fallos de pago).
2) Define 3 claves de correlación y un mapa de propietarios.
3) Implementa reglas determinísticas mínimas y un campo de enriquecimiento obligatorio (cliente, order_id).
4) Programa revisiones semanales para ajustar reglas y medir TTR y tasa de misagrupaciones.
Si necesitas herramientas para ejecutar estas fases, consulta nuestros productos en /products, explora soluciones de marketing y datos en /products/organic-marketing-engine y /products/revenue-intel-module, o lee más artículos en /blog. Para soporte o consultoría, escribe a /contact.
Mantén la correlación ligada a la ejecución: cada evento correlacionado debe acercar al equipo a una decisión o mejora. Esa es la diferencia entre menos ruido y menos incidentes reproducibles.
Lecturas relacionadas
Para seguir el mismo tema desde otros angulos operativos: