
Playbook práctico para escalamiento de tickets urgentes
Cómo diseñar un sistema de escalamiento que mueva trabajo urgente más rápido: disparadores claros, dueños explícitos, plantillas guiadas, rutas de excepción y controles de calidad.
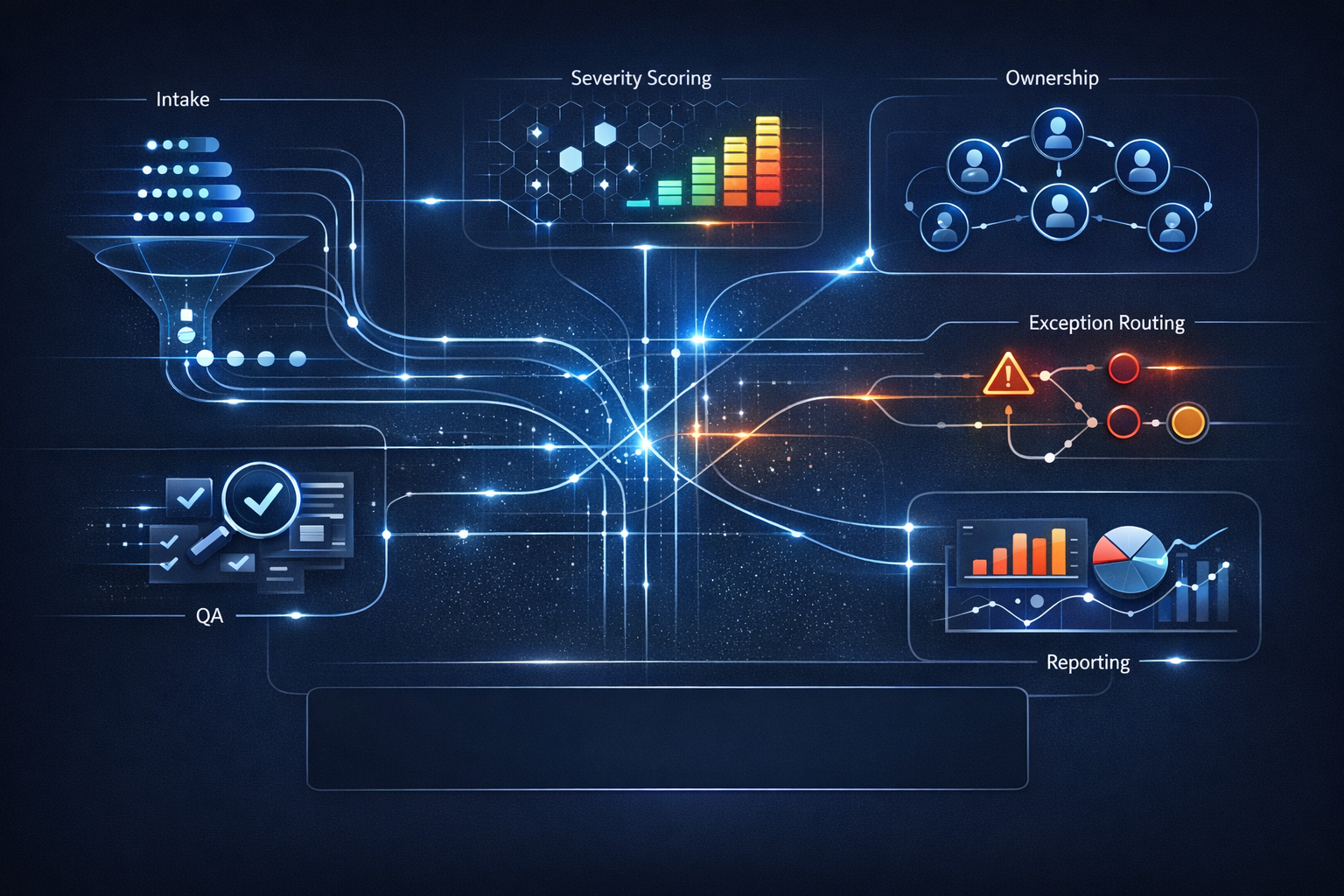
Playbook práctico para escalamiento de tickets urgentes
El trabajo urgente se atrasa cuando la señal se pierde entre herramientas: llega un ticket crítico, nadie asume la propiedad, y la siguiente acción queda en espera hasta que un cliente o un KPI revela el problema. Este playbook explica cómo transformar el manejo de incidencias en un sistema operativo repetible: define disparadores, dueños, rutas de excepción y controles que reduzcan el tiempo de resolución y aumenten la visibilidad.
Por qué fallan los procesos de escalamiento
Los síntomas más comunes son universales: hilos en chat o correo como fuente de verdad, reasignaciones manuales que añaden demora, automatizaciones ad-hoc sin trazabilidad y faltas de criterios claros para cuándo escalar. Resultado: MTTR alto, pérdida de confianza y análisis post-mortem incompletos.
Problemas frecuentes:
- Flujo encerrado en conversaciones privadas en lugar de un sistema de registro.
- Handoff manual entre equipos que provoca demoras y errores.
- Reglas de enrutamiento contradictorias o bucles de reasignación.
- Falta de métricas operativas (tiempo a reconocer, tiempo a resolver).
Si reconoces alguno de estos puntos, necesitas una capa operativa que imponga control sin eliminar la flexibilidad humana.
Capa de control operativo: qué es y por qué importa
Una capa de control operativo separa la intención (qué hay que resolver) de la ejecución (quién hace qué, cuándo). No es otra automatización puntual: es el sistema de registro, la fuente de verdad y la lógica que decide rutas, dueños y excepciones.
Funciones clave de esta capa:
- Enrutamiento determinista con fallback y failover.
- Orquestación paso a paso mediante plantillas guiadas (runbooks ligeros).
- Visibilidad consolidada y rastro de auditoría.
- Comprobaciones de calidad automáticas y gobernanza de plantillas.
Esto habilita ejecución dirigida por el sistema, trazabilidad y propiedad clara en cada paso.
Plantillas guiadas: tres ejemplos prácticos
Aquí tienes plantillas pensadas para operadores en equipos de cliente, revenue y contenido. Cada plantilla describe disparador, orquestación, dueños y controles QA.
1) Incidencia crítica en cliente de alto valor (Customer Ops)
- Disparador: Severidad=Crítica y Tier=Enterprise.
- Orquestación: crear ticket de escalamiento, notificar al on-call por canal designado, abrir sala de colaboración, adjuntar snapshot de cambios recientes.
- Dueños: propietario primario, secundario y propietario de escalamiento 24/7.
- Controles QA: propietario debe reconocer en 5 minutos; si no, failover automático.
2) Fallo en ruteo de leads (Revenue Ops)
- Disparador: Lead rechazado por automatización CRM y origen=campaña pagada.
- Orquestación: crear ticket de investigación, adjuntar logs sync, encolar a SDR o data steward.
- Dueños: data steward con SLA de 12 horas; escalado a manager de analytics si no hay respuesta.
- Beneficio: preserva fuente de la verdad para conversiones y evita pérdida de ingresos.
3) Bloqueo en publicación de contenido (Content Ops)
- Disparador: fallo en pipeline de publicación o violación de QA editorial.
- Orquestación: snapshot del contenido, notificación al editor en jefe, bloqueo temporal del flujo de publicación hasta verificación.
- Dueños: editor responsable, backup asignado.
- Controles QA: verificación previa a re-publicar y registro de cambios.
Estas plantillas deben ser pequeñas y modulares: una plantillA para escalar, otra para notificar, otra para cerrar.
Modelo operativo: reglas, propiedad y rutas de excepción
Un modelo operativo viable tiene tres capas: políticas, plantillas y controles en tiempo de ejecución.
Política (gobernanza)
- Define quién aprueba plantillas y quién puede modificar reglas.
- Usa versionado y firmas para cambios críticos.
Plantillas (diseño)
- Capturan inputs, ramas decisionales, dueños y outputs.
- Deben ser idempotentes: ejecutar la plantilla varias veces no produce acciones en conflicto.
Controles en tiempo de ejecución
- Timeouts y failover automáticos.
- Registro del sistema como source-of-truth; no se permiten reasignaciones por chat que no pasen por la capa.
Reglas prácticas de propiedad
- Cada escalamiento tiene un owner primario y un owner de respaldo con SLA definido.
- La transferencia de propiedad solo ocurre a través de la capa de control (no por correo o chat).
- Acknowledgement automático: si el owner no confirma en X minutos, se reasigna.
Rutas de excepción (ejemplos operativos)
- Excepción tipo A (conocida): vendor outage. Ruta: aplicar runbook preaprobado y notificar stakeholders.
- Excepción tipo B (desconocida): escalamiento humano para triage. Ruta: abrir una tarea de diagnóstico, asignar triage owner y crear artefacto de investigación.
Documentar las rutas de excepción en cada plantilla evita decisiones ad-hoc que rompen el flujo.
Controles de calidad y modos de fallo comunes
Añadir controles reduce riesgos. Implementa comprobaciones automáticas y pasos de verificación humana cuando proceda.
Modos de fallo habituales:
- Dueño desconocido: ticket sin acknowledgements.
- Bucles de enrutamiento: sistemas que reasignan continuamente.
- Race conditions en automatizaciones: actualizaciones concurrentes que generan pérdida de estado.
- Fallos silenciosos: notificaciones no entregadas, sin seguimiento.
- Grietas de auditoría: falta de contexto para análisis posterior.
Controles recomendados:
- Acknowledgement check: obligación de confirmar en X minutos, con escalado automático.
- Consistencia de estado: validaciones que confirmen que los campos críticos del ticket coinciden con la plantilla.
- Entrega de notificaciones: comprobación de entrega (webhook/ack) antes de continuar.
- Verificación post-escalamiento: sólo cerrar tras pasar QA y documentar resolución.
KPIs mínimos a seguir:
- Tiempo a reconocer (time-to-acknowledge).
- Tiempo a resolver (time-to-resolution).
- Número de handoffs por ticket.
- Casos de re-escalamiento por misma causa.
Implementación paso a paso
1) Discovery (1-2 sesiones de 60 minutos): mapea workflows actuales, puntos de decisión y automatizaciones existentes.
2) Definir políticas: establece gobernanza, SLAs y criterios de aprobación.
3) Diseñar plantillas mínimas: comienza con 3 plantillas (incidente crítico, fallo de ruteo, bloqueo de publicación).
4) Integrar sistemas: CRM, canales de notificación, monitoring y pipelines de datos. Revisa /products si buscas integraciones o soluciones complementarias y explora /products/revenue-intel-module para necesidades de revenue ops.
5) Piloto controlado: ejecuta plantillas en entorno controlado y recoge métricas.
6) Iterar y escalar: afina thresholds, rutas y owners con datos reales.
Consejos operativos
- Mantén plantillas pequeñas: cada una debe hacer una sola cosa y ser reutilizable.
- Observabilidad primero: crea dashboards con los KPIs básicos para detectar degradaciones.
- Gobernanza ligera: versionado y aprobaciones rápidas permiten moverse con seguridad.
Siguiente paso práctico
El siguiente paso es hacer un piloto. Selecciona un caso real, documenta el disparador, define owner y backup, crea una plantilla y pruébala durante dos semanas. Mide time-to-acknowledge y time-to-resolution y ajústala.
Para soporte o integración con herramientas existentes visita /contact. Encuentra recursos adicionales y artículos relacionados en /blog y evalúa si necesitas capacidades de marketing o contenido en /products/organic-marketing-engine.
Este playbook busca que tu equipo pase de reacciones ad-hoc a ejecución sistemática: menos fricción, mayor visibilidad y dueños claros en cada escalamiento.
Lecturas relacionadas
Para seguir el mismo tema desde otros angulos operativos: