
Sincronización CRM → ERP para agencias: cómo operar sin incendio diario
Recupera el control de la sincronización entre CRM y ERP en agencias. Propón un modelo operativo con dueños, reglas, rutas de excepción y pasos prácticos para reducir errores y acelerar facturación.
Sincronización CRM → ERP para agencias: cómo operar sin incendio diario
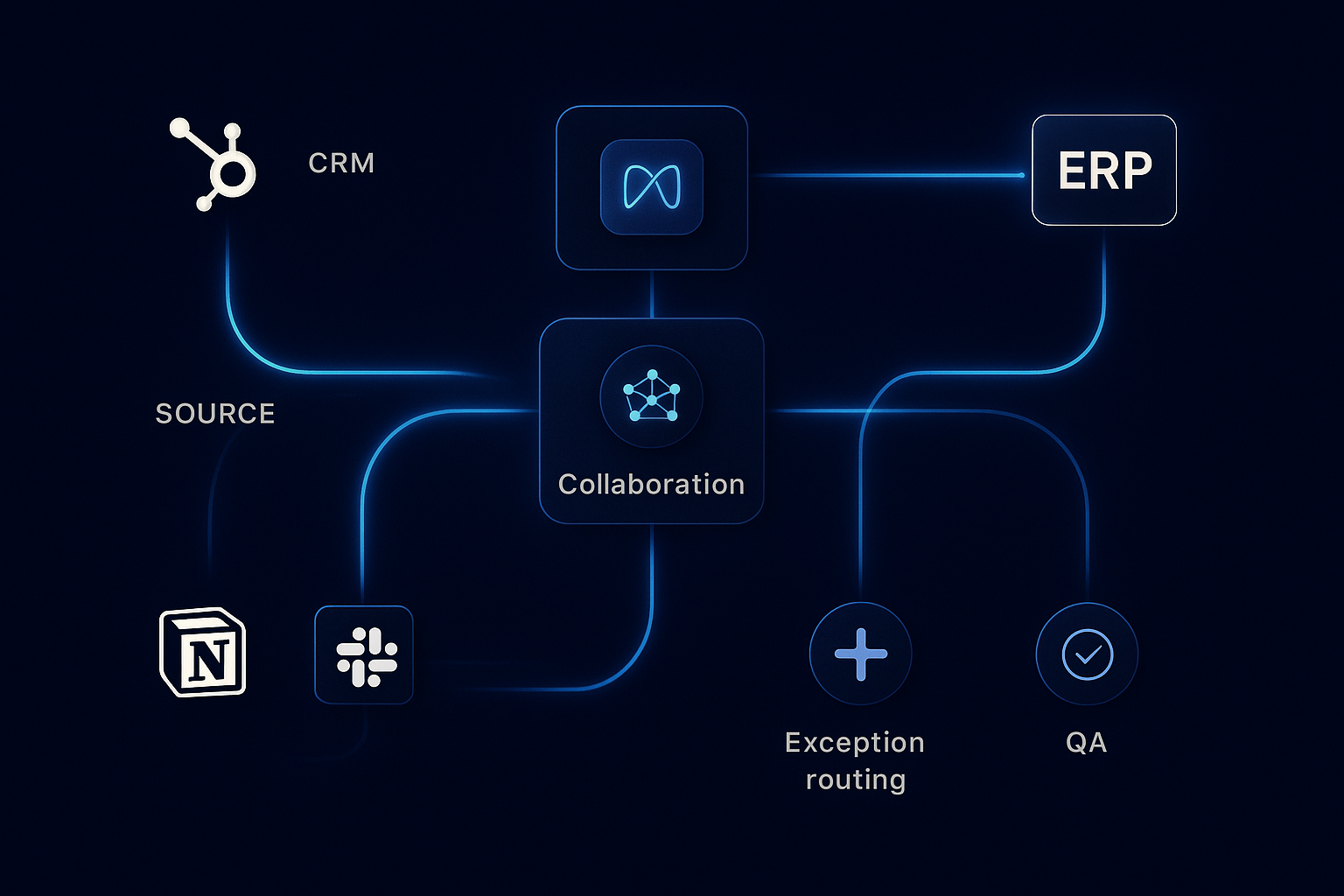
La sincronización entre CRM y ERP deja de ser un problema cuando existe una capa operativa que hace visibles los responsables, las excepciones y el siguiente paso antes de que facturas, cuentas o pedidos dejen de coincidir. Esta guía explica un marco práctico para operadores de agencia: decisiones operativas, rutas de excepción, controles de calidad y un plan reproducible para detener la reparación manual constante.

El problema que resolvemos
Las agencias gestionan clientes y proyectos con al menos tres sistemas: CRM (pipeline y contratos), ERP (facturación y contabilidad) y plataformas de proyecto/entrega. Cuando la sincronización CRM→ERP falla, aparecen estos síntomas comunes:
- Duplicados de clientes en ERP que generan confusión contable.
- Códigos de facturación incompletos o tarifas inconsistentes.
- Retraso entre firma del contrato y la primera factura.
- Scripts ad hoc y planillas como parche temporal.
Para un operador hispanohablante, la prioridad es simple: facturar a tiempo sin operaciones manuales interminables y con trazabilidad suficiente para auditoría financiera.
Por qué una capa operativa en vez de integraciones punto a punto
Las integraciones directas fallan cuando no hay reglas compartidas ni dueños claros. Una capa operativa (orquestador entre CRM y ERP) aporta:
- Resiliencia: reintentos, idempotencia y colas manejadas fuera de los sistemas fuente.
- Claridad de propiedad: quién resuelve una excepción y en cuántas horas.
- Velocidad: menos tiempo hasta la primera factura y menos trabajo manual.
- Cumplimiento: registros y auditoría accesibles para finanzas.
Decisión práctica: prioriza diseños con confirmación asíncrona (event-driven) y idempotencia antes de optimizar latencia en tiempo real.
Historias reales: antes y después (ejemplos)
Ejemplo 1 — Antes (patchwork):
- Una agencia mediana usaba un conector nativo + script casero. Cuando se cerraba una venta, el account manager debía añadir manualmente el código de facturación. El script duplicaba clientes y finanzas tardaba 2–3 días en conciliar.
Ejemplo 2 — Después (capa operativa):
- Un orquestador valida la ficha de cliente en el momento de la firma, enriquece con código ERP y envía un payload idempotente. Las excepciones llegan a un canal de colaboración con acciones rápidas y la conciliación mensual pasa de días a horas.
Estos ejemplos muestran dos decisiones operativas clave: publicar contratos de datos (qué campos son obligatorios) y definir SLA de sincronización.
Marco operativo: responsabilidades y reglas
Roles mínimos:
- Propietario CRM: lifecycle de lead a contrato y datos canónicos de contacto.
- Propietario ERP: catálogo contable, tarifas y entrega de facturas.
- Sync owner (operaciones): reglas de mapeo, SLA, runbooks.
- Dueño de excepciones (Finanzas o Sales Ops): triage y resolución.
Reglas operativas (ejemplos concretos):
- Cada entidad (cliente, contrato, línea) tiene un contrato de datos publicado con campos obligatorios y tipos.
- SLA de sincronización: máximo 4 horas para cambios críticos, 24h para errores que no impactan facturación.
- TTR (time to resolution) para errores con impacto de facturación: 24 horas.
Decisión operativa: mantener el repositorio de mapeos bajo control del Sync owner; sólo ellos pueden cambiar transformaciones en producción.
Patrones de diseño de sincronización
Patrón A — Cliente canónico y enriquecimiento
Flujo:
- Evento de CRM: crear/actualizar cliente.
- Orquestador valida esquema, reserva o busca código ERP y envía la creación.
- Orquestador persiste el mapeo CRM↔ERP y devuelve confirmación al CRM.
Patrón B — Facturación orientada por contrato (contract-first)
Flujo:
- Firma en CRM dispara composición de metadatos de factura (términos, PO, tarifa).
- Orquestador valida ítems y GL mappings; crea la factura en ERP.
- Confirmación y registro de trazas para auditoría.
Patrón C — Manejo colaborativo de excepciones
Flujo:
- Error validado → notificación estructurada en canal colaborativo con botones accionables.
- Sales Ops / Finanzas triage desde el mensaje; orquestador reintenta si se aprueba.
Implementación práctica: envía alertas con contexto accionable a canales integrados y adjunta un enlace a la ficha del incidente.
Rutas de excepción y playbooks
Rutas comunes y acciones:
- Error de validación (campo obligatorio faltante): enviar a Sales Ops con button “Completar datos”; mantener evento en cola por 48 horas.
- Conflicto de mapeo (cliente duplicado): crear tarea de fusión en CRM, notificar al propietario CRM y posponer escritura a ERP hasta resolución.
- Rechazo ERP (asiento inválido): mover a dead-letter queue, etiquetar con motivo y notificar a Finanzas para resolución manual.
Playbook corto para una excepción de facturación:
- Notificación estructurada en Slack/Teams con razón y payload.
- Sales Ops revisa y corrige la ficha o aprueba la excepción.
- Orquestador reintenta la operación y registra la acción para auditoría.
Enlaces relevantes de Meshline para operadores: revisa /products y /products/revenue-intel-module para capacidades que facilitan mapeos y alertas automatizadas.
Controles de calidad y QA operativo
Checks automáticos sugeridos:
- Pruebas sintéticas diarias: crear/actualizar cliente y confirmar mapeo.
- Reconciliación programada: comparar IDs canónicos CRM vs ERP y generar discrepancias.
- Monitoreo de SLA: dashboards con tiempos promedio a primera factura.
- Registros estructurados: cada evento debe incluir payload, transformaciones aplicadas y responsable para auditoría.
Acciones de auditoría:
- Runbooks para rollback y replay de eventos.
- Lista de cambios autorizados en mapeos con control de acceso.
Implementación en 8 semanas (patrón reproducible)
Semana 0–1: Descubrimiento
- Entrevistas con Ventas, Finanzas, TI.
- Inventario de campos y fallos frecuentes.
- Crear contratos de datos iniciales (cliente, contrato, línea).
Semana 1–2: Diseño
- Decidir eventos vs batches.
- Definir idempotencia, SLA y error schemas.
- Publicar matriz de responsabilidades.
Semana 2–4: Sandbox
- Implementar mapeos canónicos y validaciones.
- Activar modo dry-run contra ERP en staging.
Semana 4–5: Pruebas
- Pruebas E2E sintéticas y conciliaciones.
- Ajustes de reglas y tolerancias.
Semana 5–6: Piloto
- Piloto por unidad de negocio; medir TTB (time-to-bill) y errores.
Semana 6–8: Rollout y runbooks
- Documentar runbooks, accesos y escalado.
- Formación para propietarios de sistemas y equipos de excepción.
Controles finales y siguientes pasos prácticos
Controles mínimos para salir de piloto:
- Reconciliación diaria automatizada con errores < 1%.
- TTR acordado y medible para errores de facturación.
- Runbooks publicados y equipo entrenado.
Siguiente paso práctico: agenda una demo técnica en /contact para modelar tus contratos de datos y probar un flujo en sandbox. Mientras tanto, consulta /products/organic-marketing-engine y /products/revenue-intel-module para ver módulos que complementan la automatización de ingresos.
Si quieres más plantillas y ejemplos, visita nuestro archivo de casos en /blog o solicita un taller de descubrimiento para tu agencia a través de /contact.
Lecturas relacionadas
Para seguir el mismo tema desde otros angulos operativos: