
Control de aprobaciones de prompts: guía operativa para equipos
Guía práctica para diseñar un proceso de aprobación de prompts que combine rapidez y trazabilidad: reglas de propiedad, rutas de excepción, controles de calidad y métricas accionables.
Control de aprobaciones de prompts: guía operativa para equipos
En entornos donde los modelos generan texto que impacta clientes, marca o cumplimiento, la aprobación de prompts deja de ser un trámite y se convierte en un control operativo clave. Esta guía explica cómo diseñar un flujo que: identifique responsables, reduzca cuellos de botella, registre decisiones y convierta aprobaciones en un mecanismo de aprendizaje continuo.
¿Qué entendemos por "control de aprobaciones de prompts"?
Es un conjunto de políticas y controles en tiempo de ejecución que definen:
- Qué prompts requieren revisión humana y en qué momento (antes o después del modelo).
- Quién toma la decisión (propietarios y backups) y bajo qué criterios.
- Las métricas que enlazan una aprobación con resultados observables (cumplimiento, tasa de conversión, incidentes).
- Dónde y cómo se registra cada decisión para permitir auditoría y consultas posteriores.
Un control bien diseñado no sólo bloquea riesgos: también permite relajar reglas cuando las métricas lo validan. Integra la aprobación con la capa operativa que atrapa metadatos, versiones y resultados.
Por qué importa: objetivos medibles y equilibrio riesgo/velocidad
La aprobación no es un paso administrativo; es el punto de control donde se equilibra rapidez frente a riesgo. Algunas métricas a relacionar con las aprobaciones:
- Puntuación de cumplimiento para contenido regulado.
- Porcentaje de salidas que cumplen las guías de marca.
- Variación en CTR o conversión tras cambios en prompts.
- Tiempo medio de resolución para interacciones de soporte.
- Incidentes por cada 10.000 prompts procesados.
Cuando las aprobaciones actualizan estas métricas, el equipo puede ajustar rutas y SLAs para optimizar resultados.
Dónde suele romperse el flujo: fallos comunes y cómo evitarlos
1) Reglas de propiedad poco claras
- Síntoma: aprobaciones estancadas.
- Solución: crear una taxonomía (por producto, riesgo, dominio) y reglas deterministas que asignen propietarios y backups automáticos.
2) Cola de revisión saturada
- Síntoma: operadores eluden el proceso.
- Solución: triage automático, auto-aprobación de low-risk, batching y rutas prioritarias para lo urgente.
3) Criterios de decisión no accionables
- Síntoma: decisiones inconsistentes entre revisores.
- Solución: plantillas y checklist objetivo (lista de términos prohibidos, cláusulas legales obligatorias).
4) Mala trazabilidad
- Síntoma: no hay aprendizaje ni se puede auditar decisiones.
- Solución: registrar prompt, versión, decisión, justificación y resultados vinculados.
5) Escalada complicada
- Síntoma: excepciones se estancan esperando expertos.
- Solución: rutas automáticas de escalado por riesgo y SLAs.
6) Deriva entre intención y despliegue
- Síntoma: cambios posteriores al prompt aprobado que no se revalidan.
- Solución: control de versiones con bloqueo de despliegue si la versión cambia sin nueva aprobación.
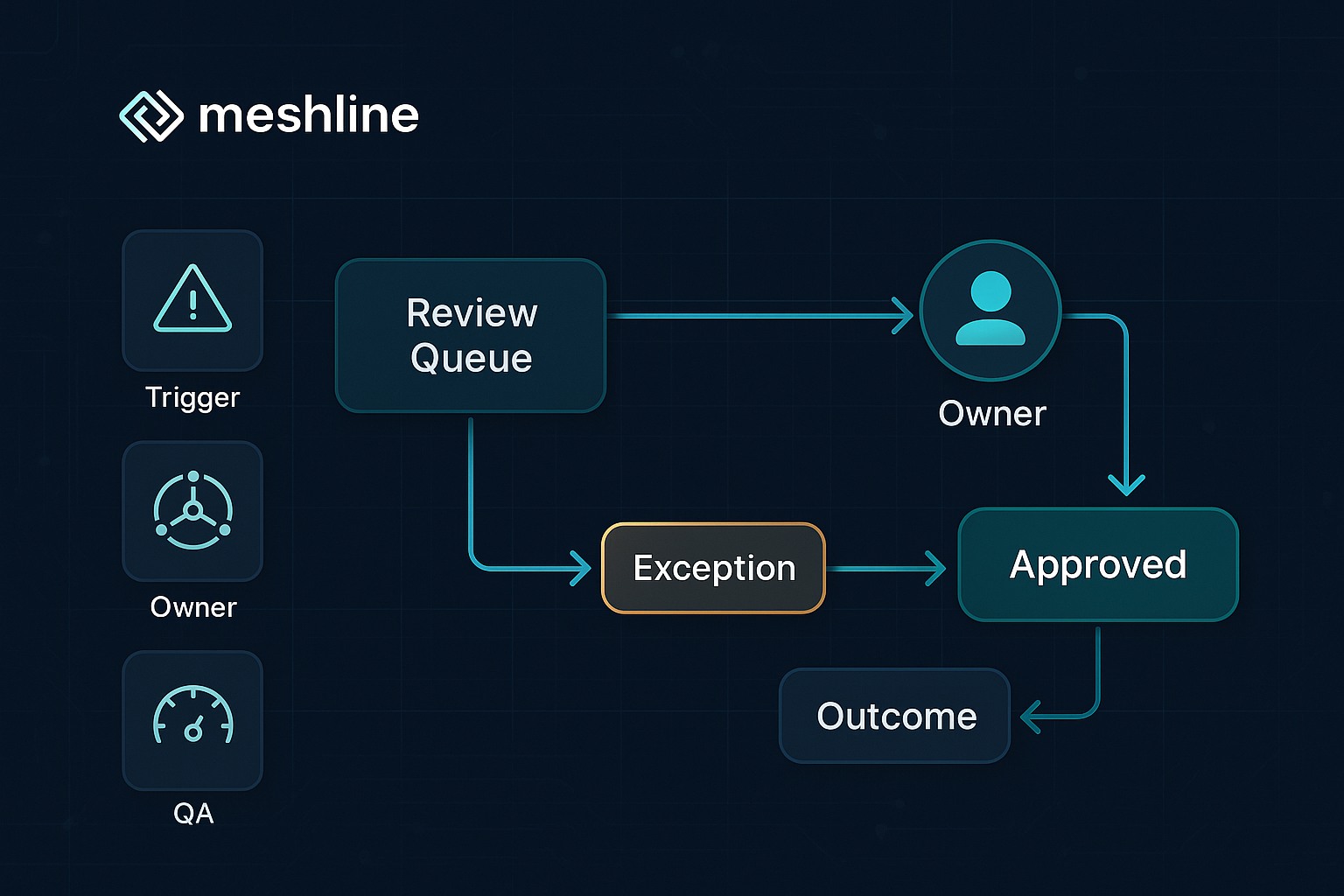
Modelo operacional: Disparo -> Propietario -> Excepción -> Resultado
Estructura mínima y reproducible que conviene implementar en la capa operativa:
- Disparo: evento que introduce un prompt en la cola (ej.: envío desde marketing, detección por filtros automáticos, re-revisión programada).
- Propietario: rol o persona determinada por reglas (riesgo, dominio, producto).
- Excepción: rutas alternativas si el propietario rechaza o identifica incumplimientos (legal, reescritura, bloqueo urgente).
- Resultado: estado final (Aprobado, Aprobado con cambios, Rechazado, Escalado, Auto-aprobado) y actualización de métricas asociadas.
Cada flujo debe ser auditable y producir metadatos que permitan conectar la decisión con los resultados.
Ejemplos prácticos y decisiones operativas (casos reales adaptados)
Caso A — Marketing en producto no regulado
- Disparo: prompt para copy de campaña «Paid Social: Landing A/B». Riesgo: bajo.
- Decisión operativa: auto-aprobar si coincide con plantillas permitidas. Si no, pasar a revisión de Sales Enablement.
- Excepción: si se detectan reclamaciones por derechos de autor, escalar a legal.
- Métrica vinculada: CTR y tasa de conversión a 7 días.
Caso B — Mensajes con implicaciones legales (finanzas)
- Disparo: prompt con tasas o condiciones de préstamo. Riesgo: alto.
- Decisión operativa: bloqueo automático hasta aprobación de Compliance.
- Rutas de excepción: backup legal tras 8 horas SLA; si excede 24 horas, generar bloqueo temporal y notificar liderazgo.
- Métrica vinculada: tasa de rechazo de compliance y tiempo medio a publicación.
Caso C — Soporte al cliente asistido por IA
- Disparo: asistente sugiere respuesta a un caso sensible.
- Decisión operativa: revisión en tiempo real por un peer o supervisor en función del riesgo de la consulta.
- Excepción: si se detecta posible fuga de datos, bloqueo inmediato y escalado al equipo de seguridad.
- Métrica vinculada: tiempo de resolución y tasa de re-apertura de tickets.
En la práctica, estos casos se integran con herramientas internas y productos: conecta aprobaciones con tu pipeline de contenido y con módulos como /products/organic-marketing-engine o /products/revenue-intel-module para medir impacto comercial.
Checklist de implementación (paso a paso)
1) Definir taxonomía y niveles de riesgo
- Categorizar prompts y establecer criterios objetivos para cada nivel.
2) Asignar reglas de propiedad y SLAs
- Mapear roles, backups y tiempos límites de decisión.
3) Construir punto de entrada en la capa operativa
- Capturar metadatos: autor, texto, contexto, versión, objetivo.
4) Implementar triage automático y controles estáticos
- Filtros: términos prohibidos, detección de PII, checks regulatorios.
5) Crear plantillas y criterios de aceptación
- Checklists por categoría: legal, marca, seguridad, factualidad.
6) Definir rutas de excepción
- Reescritura, legal, bloqueo temporal, notificación a stakeholders.
7) Registrar y enlazar resultados
- Guardar decisiones y vincular métricas post-despliegue.
8) Revisar y ajustar semanalmente
- Empezar con un piloto y adaptar reglas según evidencias.
Si necesitas soporte técnico o integrar estas prácticas con tus herramientas, consulta /products o contacta al equipo en /contact. Para más artículos de referencia, visita nuestro catálogo en /blog.
Métricas y controles de calidad: qué medir y cómo actuar
Operacionales
- Latencia de aprobación (mediana y P95).
- Profundidad de cola por nivel de riesgo.
- Cumplimiento de SLAs (porcentaje dentro de plazo).
Calidad
- Tasa de rechazo por propietario y categoría.
- Consistencia entre revisores (acuerdo en muestras comparadas).
- Violaciones post-deploy por cada 10.000 prompts.
Negocio
- Impacto en conversión o métricas de revenue.
- Tasa de quejas o cancelaciones relacionadas con contenido.
Cómo actuar
- Si sube la latencia: aumentar auto-aprobación para low-risk y mejorar triage.
- Si sube la tasa de violaciones: endurecer checks estáticos y revisar plantillas.
- Si hay baja consistencia entre revisores: mejorar checklists y formar revisores.
Siguiente paso práctico (piloto de 30 días)
1) Selecciona 3 categorías de prompts (ej.: marketing, soporte, legal).
2) Define reglas simples de riesgo (bajo/medio/alto) y asigna propietarios con backups.
3) Establece SLAs (ej.: 2h para bajo, 8h para medio, 24h para alto).
4) Instrumenta métricas básicas: latencia, tasa de rechazo, incidentes post-deploy.
5) Revisa resultados cada semana y ajusta plantillas y rutas de excepción.
Al terminar el piloto tendrás evidencia sobre dónde afinar reglas, qué automatizar y qué roles añadir. Si quieres apoyo para integrar estas prácticas a tus sistemas o productos, revisa /products o contacta a nuestro equipo en /contact.
Notas finales: una aprobación efectiva es auditable, reversible y ligada a resultados. Diseña flujos que faciliten la operativa diaria, no que la conviertan en un cuello de botella.
Lecturas relacionadas
Para seguir el mismo tema desde otros angulos operativos: